Hemos recibido una nota de prensa por parte de Google, os la dejamos a continuación:
Mejorando el reconocimiento del habla en los contact centers
Los contact centers son fundamentales para muchas empresas, y la tecnología desempeña un papel importante a la hora de ayudarles a ofrecer una atención al cliente excepcional. Este mes de julio, anunciamos Contact Center AI para ayudar a las empresas a aplicar la inteligencia artificial con el objetivo de mejorar la experiencia del contact center. Hoy anunciamos una serie de actualizaciones de las tecnologías que sustentan la solución Contact Center AI -en concreto, Dialogflow y Cloud Speech-to-Text– y mejoran la precisión del reconocimiento de voz en más de un 40% en algunos casos para dar un mejor soporte a los clientes y a los agentes que les ayudan.
Estas actualizaciones incluyen:
- Adaptación automática del habla en Dialogflow (beta)
- Mejoras en el modelo de reconocimiento de voz para IVRs y agentes virtuales basados en teléfono en Cloud Speech-to-Text
- Adaptación manual del habla más rica en Dialogflow y Cloud Speech-to-Text (beta)
- Transmisión de secuencias en la nube de voz a texto (beta)
- Compatibilidad con formatos de archivo MP3 en Cloud Speech-to-Text
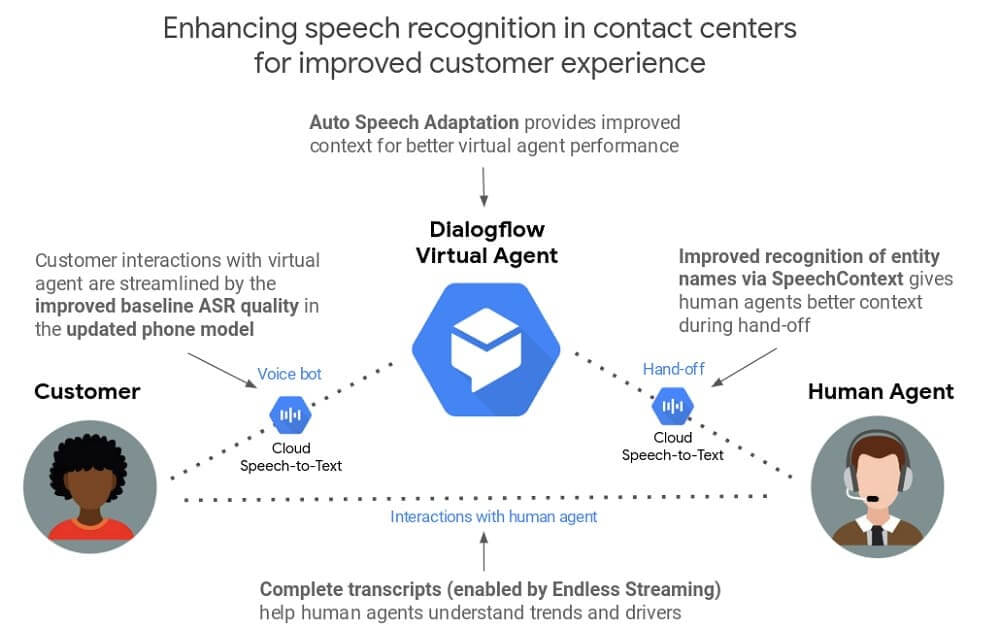
Mejorando el reconocimiento del habla en los agentes virtuales
Los agentes virtuales son una poderosa herramienta para los contact center, que proporciona una mejor experiencia de usuario las 24 horas del día, a la vez que reduce los tiempos de espera. Sin embargo, ejecutar el reconocimiento automático de voz (ASR) que requieren los agentes virtuales es mucho más difícil en líneas telefónicas ruidosas que en el laboratorio. E incluso con altas tasas de precisión de reconocimiento (~90%), en ocasiones el ASR puede resultar en una experiencia frustrante para el cliente.
Para ayudar a los agentes virtuales a comprender rápidamente lo que necesitan los clientes y responder con precisión, estamos introduciendo una nueva e interesante función en Dialogflow.
Adaptación automática del habla en Dialogflow Beta
Al igual que el conocimiento del contexto de una conversación facilita la comprensión mutua entre las personas, el ASR mejora cuando la IA subyacente comprende el contexto que hay detrás de lo que dice uno de los participantes en la conversación. Utilizamos el concepto adaptación del habla para describir este proceso de aprendizaje.
Dialogflow, nuestro paquete de desarrollo para crear experiencias de conversación automatizadas, puede ayudar a los agentes virtuales a responder con mayor precisión gracias al conocimiento del contexto. Por ejemplo, si el agente Dialogflow supiera que el contexto es «pedir una hamburguesa» y que «queso» es un ingrediente común de las hamburguesas, probablemente entendería que el usuario quiere decir «queso» y no «estos». Del mismo modo, si el agente virtual supiera que el término «envío» es un término común en el contexto de una devolución de producto, no lo confundiría con las palabras «sitio» o «recibo».
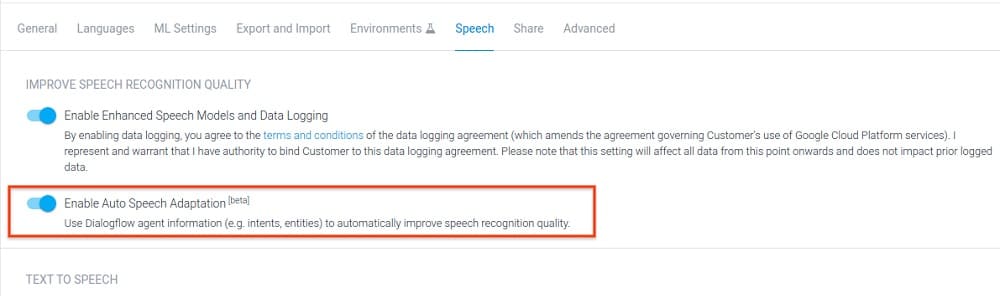
Para alcanzar ese objetivo, la nueva función de Adaptación automática del habla de Dialogflow ayuda al agente virtual a comprender automáticamente el contexto teniendo en cuenta todas las frases de entrenamiento, entidades y otra información específica del agente. En algunos casos, esta característica puede aumentar un 40% o más la precisión de forma relativa.
Es fácil activar la Adaptación automática del habla: basta con hacer clic en el interruptor «on» de la consola Dialogflow (desactivado de forma predeterminada), ¡y ya está todo listo!
Mejoras en las bases de Cloud Speech-to-Text para IVRs y agentes virtuales basados en teléfonos
En abril de 2018, introdujimos modelos prefabricados para mejorar la precisión de la transcripción de las llamadas telefónicas y de vídeo. Más adelante, el pasado mes de febrero, anunciamos la disponibilidad de estos modelos para todos los clientes, no sólo para aquellos que habían optado por nuestro programa de registro de datos. Hoy en día, hemos optimizado aún más nuestro modelo para telefonía, teniendo en cuenta las expresiones cortas más habituales en las interacciones con agentes virtuales basados en teléfono. El nuevo modelo es ahora un 15% más preciso para el inglés de EE.UU., en términos relativos, más allá de las mejoras que anunciamos anteriormente. La aplicación de la adaptación del habla también puede proporcionar mejoras adicionales. Añadimos constantemente mejoras de calidad en nuestra hoja de ruta – algo de lo que se beneficia automáticamente cualquier IVR o agente virtual basado en teléfonos, sin necesidad de realizar cambios en el código – y seguiremos compartiendo más información sobre estas actualizaciones en futuras publicaciones en el blog.
Mejorando la transcripción para ayudar a los agentes humanos
Una transcripción precisa de las conversaciones con los clientes puede ayudar a los agentes humanos a responder mejor a sus solicitudes, lo que resulta en un mejor servicio de atención al cliente. Estas actualizaciones mejoran la calidad de la precisión de la transcripción para ayudar a los agentes humanos.
Adaptación manual del habla más rica en Cloud Speech-to-Text
Al utilizar Cloud Speech-to-Text, los desarrolladores utilizan los llamados parámetros SpeechContext para proporcionar información contextual adicional que puede hacer que la transcripción sea más precisa. Este proceso de ajuste puede ayudar a mejorar el reconocimiento de frases que son habituales en función del caso de uso concreto. Por ejemplo, la línea de atención al cliente de una empresa puede querer reconocer mejor los nombres de sus propios productos.
Hoy anunciamos tres actualizaciones, todas ellas en beta, que hacen que SpeechContext sea aún más útil para afinar manualmente el ASR y mejorar la precisión de la transcripción. Estas nuevas actualizaciones están disponibles en las APIs Cloud Speech-to-Text y Dialogflow.
SpeechContext classes Beta
Classes son entidades prefabricadas que reflejan conceptos populares o comunes y le dan a Cloud Speech-to-Text el contexto que necesita para reconocer y transcribir con mayor precisión la entrada de voz. El uso de classes permite a los desarrolladores sintonizar el ASR con una lista completa de palabras a la vez, en lugar de añadirlas una por una.
Por ejemplo, digamos que hay una frase que normalmente aparece en una transcripción, «Son las doce y cincuenta y una». Basándose en el caso práctico de uso, se podría utilizar una clase SpeechContext para refinar la transcripción de varias maneras diferentes:
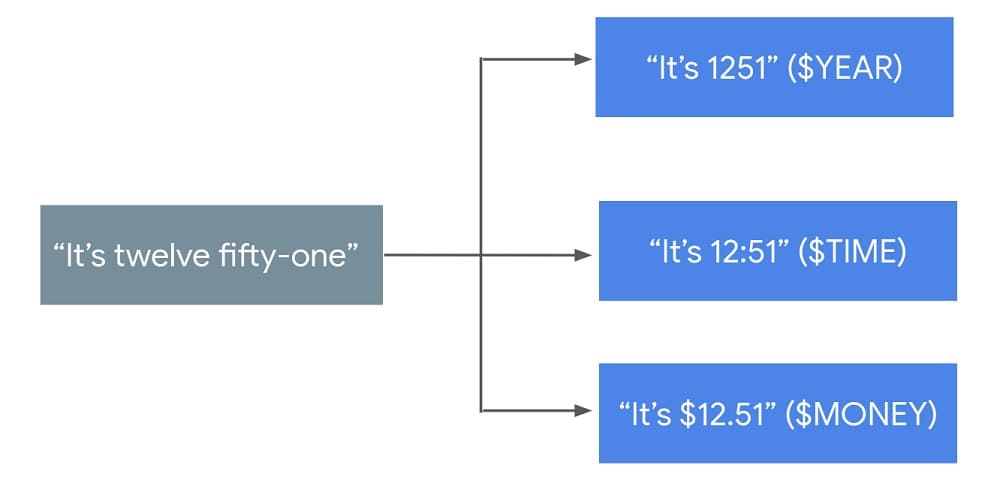
Hay diferentes classes disponibles para establecer el contexto de secuencias de dígitos, direcciones, números y monedas – puedes ver la lista completa aquí.
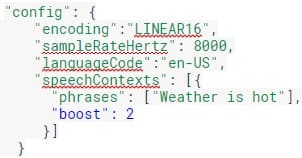
SpeechContext boost Beta
Sintonizar el reconocimiento de voz con herramientas como SpeechContext aumenta la probabilidad de que ciertas frases sean capturadas, lo que reducirá el número de falsos negativos (cuando se menciona una frase, pero no aparece en la transcripción), pero también puede aumentar potencialmente el número de falsos positivos (cuando una frase no se menciona, pero aparece en la transcripción). La nueva función «boost» permite a los desarrolladores utilizar la mejor adaptación del habla para su caso de uso.
Example:
SpeechContext amplía su límite de frases (beta)
Como parte del proceso de ajuste, los desarrolladores utilizan «indicios» para aumentar la probabilidad de que las palabras o frases de uso común relacionadas con su negocio o vertical sean capturadas por el ASR. El número máximo de indicios de frases por solicitud de API se ha multiplicado por diez, de 500 a 5.000, lo que significa que una empresa puede optimizar la transcripción de miles de palabras de su jerga (como los nombres de productos) que son poco comunes en el lenguaje cotidiano.
Además de estas nuevas características relacionadas con la adaptación, anunciamos otras mejoras muy solicitadas que mejoran la experiencia de producto para todos.
Streaming ilimitado (beta) en Cloud Speech-to-text
Desde que introdujimos Cloud Speech-to-Text hace casi tres años, el streaming de larga duración ha sido una de las principales peticiones de los usuarios. Hasta ahora, Cloud Speech-to-Text sólo soportaba la transmisión de audio en segmentos de un minuto, lo que resultaba problemático para aquellos casos en los que se necesitaban transcripciones de larga duración como reuniones, vídeo en directo y llamadas telefónicas. Hoy, el límite de tiempo de la sesión se ha elevado a 5 minutos. Además, la API permite ahora a los desarrolladores iniciar una nueva sesión de streaming desde donde se dejó la anterior, lo que hace que la transcripción automática en directo sea infinita en duración y se desbloqueen una serie de nuevas posibilidades relacionadas con el audio de larga duración.
El formato MP3 compatible con la versión beta de Cloud-Speech-to-Text
Hasta el momento, Cloud-Speech-to-Text ha soportado siete formatos de archivos diferentes (aquí el listado). Hasta ahora, el procesamiento de archivos MP3 exigía expandirlos primero al formato LINEAR16, lo que requiere mantener una infraestructura adicional. Cloud Speech-to-Text es ahora compatible con MP3 de forma nativa, por lo que no es necesario realizar conversiones adicionales.
El uso de la IA en Woolworths para mejorar la experiencia del contact center
Desde 1924, Woolworths es el mayor minorista de Australia, con más de 100.000 empleados. «En colaboración con Google, hemos creado una nueva solución de agente virtual basada en Dialogflow y Google Cloud AI. Desde el principio hemos experimentado un rendimiento excepcional”, afirma Nick Eshkenazi, Director de Tecnología Digital de Woolworths. «Nos ha impresionado especialmente el nivel de precisión en frases largas, el reconocimiento de las marcas e incluso la comprensión de formatos complejos, como equiparar ‘150g’ con 150 gramos”.
«Además, la adaptación automática del habla mejoró la experiencia significativamente y nos permitió responder adecuadamente a más consultas de los clientes», dice Eshkenazi. «En el pasado, nos llevaba meses crear una experiencia IVR de alta calidad. Ahora podemos crear experiencias sólidas en algunas semanas y hacer ajustes en cuestión de minutos».
«Por ejemplo, hace poco queríamos informar a los clientes sobre una interrupción de la red que afectaba a nuestro hub de clientes y pudimos informarles rápidamente mediante mensajes añadidos al agente virtual. Esta nueva solución proporciona a nuestros clientes respuestas instantáneas sin periodos de espera, lo que también les ayuda a contactar de manera automática con las personas adecuadas cuando se necesita hablar personalmente con un agente.»
Mirando hacia el futuro
Nos entusiasma ver cómo estos avances en el reconocimiento de voz mejoran la experiencia del cliente en los contact centers, independientemente de su tamaño y características, tanto si están trabajando con uno de nuestros socios para implementar soluciones de IA o están adoptando un nuevo enfoque DIY utilizando nuestra suite de IA conversacional. Puedes obtener más información en los siguientes enlaces:










