
NVIDIA ha anunciado nuevas optimizaciones para su plataforma Blackwell centradas en reducir el coste de inferencia de modelos de IA. En DeepSeek V4, el coste por millón de tokens en GB300 NVL72 habría pasado de 0,30$ a 0,06$, una mejora de hasta 5 veces.
La compañía vuelve a insistir en que el coste por token es la métrica clave para medir el TCO de la IA. Blackwell no mejora solo por hardware, sino por una pila completa con TensorRT-LLM, Dynamo, CUDA, NVLink, NVFP4 y optimizaciones de inferencia distribuida.
El coste por token vuelve a ser la métrica central
En inferencia de IA, hablar solo de FLOPs o de potencia bruta ya no sirve para medir el valor real de una plataforma. El coste por token refleja cuántas respuestas puede generar un sistema por dólar, mezclando rendimiento, energía, ocupación, memoria, software y escala.
NVIDIA usa DeepSeek V4 como escaparate porque es un modelo exigente, orientado a razonamiento, código, contexto largo y cargas agénticas. Si una plataforma reduce coste en un modelo frontier, el mensaje para proveedores cloud e inferencia es mucho más fuerte que una simple prueba sintética.
La mejora anunciada es agresiva: de 0,30$ a 0,06$ por millón de tokens en GB300 NVL72. Ese salto no viene de cambiar el chip en un mes, sino de exprimir mejor el sistema completo mediante software, planificación, memoria e interconexión.
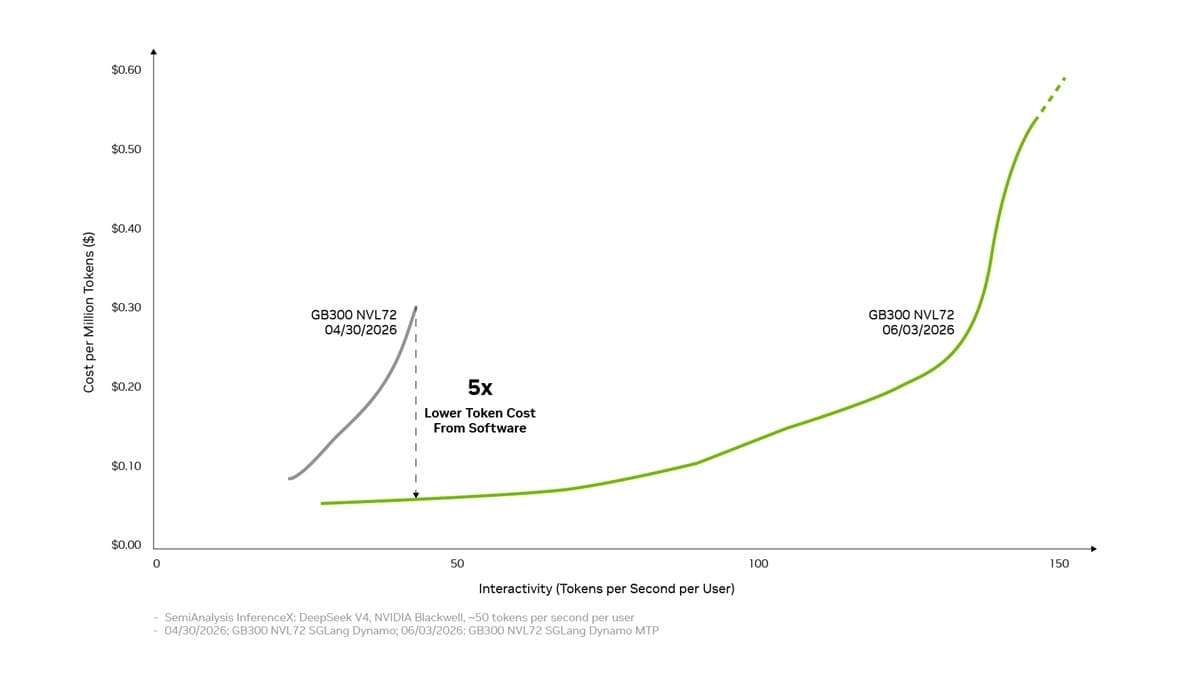
Blackwell mejora por software, no solo por silicio
El punto más interesante es que NVIDIA presenta la mejora como una victoria de pila completa. Blackwell GB200 y GB300 ganan rendimiento cuando el software coordina mejor GPU, memoria, red, kernels y ejecución distribuida, no solo cuando aumenta la potencia pico del acelerador.
Esto es importante porque muchos clientes compran infraestructura de IA esperando que mejore con el tiempo. Si TensorRT-LLM, Dynamo y las librerías de inferencia extraen más tokens por segundo del mismo hardware, el coste operativo cae sin renovar racks, algo muy atractivo para nubes y proveedores.
La compañía habla de optimizaciones acumuladas que convierten mejoras individuales en rendimiento de sistema. Fusión de kernels, solapamiento de cómputo y comunicación, gestión de memoria y orquestación distribuida pueden parecer detalles internos, pero juntos determinan cuántos tokens salen por segundo.
TensorRT-LLM y Dynamo son piezas clave
TensorRT-LLM aparece como una de las herramientas principales para acelerar DeepSeek V4 en Blackwell, permitiendo optimizar ejecución, kernels y rutas de inferencia. Baseten, por ejemplo, habría usado esta librería para servir DeepSeek V4 Pro con hasta un 50% más de tokens por segundo.
Dynamo cumple otro papel dentro de la pila. El framework gestiona inferencia distribuida, escalado y asignación de GPUs, ayudando a que equipos como Cognition ejecuten cargas de refuerzo o agentes sin tener que construir toda la infraestructura desde cero.
La ventaja para NVIDIA es doble. No vende solo GPUs, sino una capa de software que reduce fricción de despliegue, algo esencial cuando los clientes quieren pasar de benchmarks a endpoints de producción con latencia, coste y estabilidad controlados.
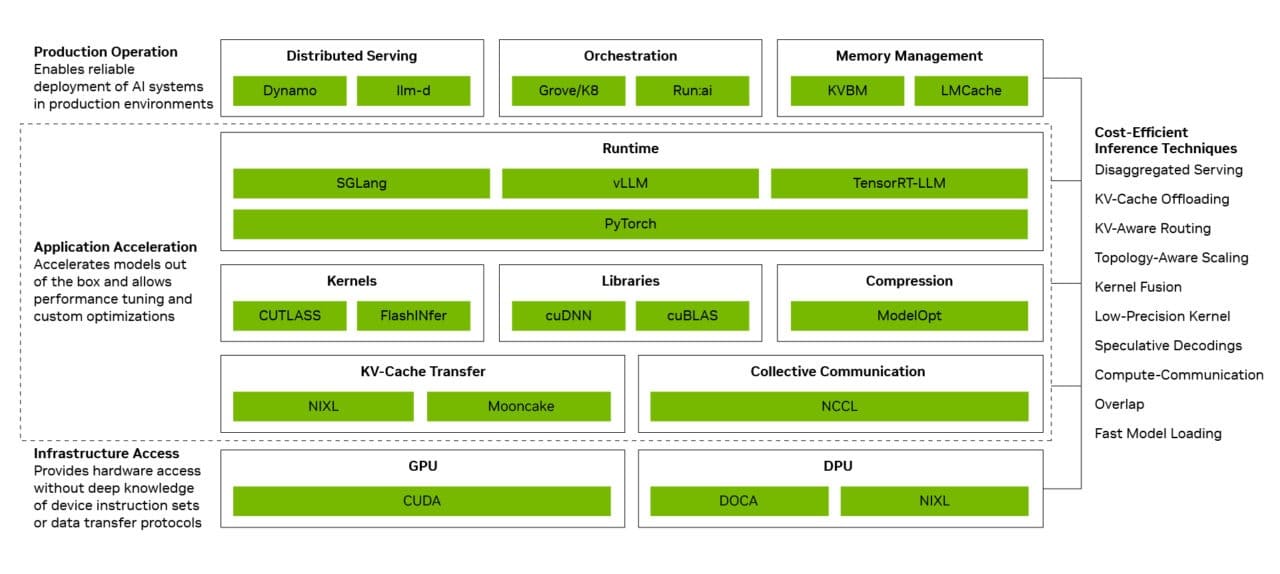
Tres capas para convertir optimización en rendimiento real
NVIDIA divide la mejora en tres capas: operación de producción, aceleración de aplicación y acceso a infraestructura. La operación de producción coordina la inferencia distribuida, la orquestación, el autoescalado y la gestión de memoria, para que el sistema use los recursos adecuados en cada carga.
La aceleración de aplicación se centra en ejecutar modelos con alto rendimiento y margen de ajuste. Aquí entran optimizaciones como solapar cómputo y comunicación, fusionar kernels y ajustar runtime, algo clave para que DeepSeek V4 mantenga throughput sin disparar latencia.
La tercera capa es el acceso a infraestructura. CUDA, red, memoria, GPUs y sistemas NVIDIA quedan expuestos sin obligar al desarrollador a gestionar cada instrucción o protocolo de transferencia, reduciendo complejidad y aumentando el rendimiento real de la plataforma.
Estas tres capas explican por qué NVIDIA insiste tanto en la idea de pila completa. El salto de Blackwell no depende de una única optimización aislada, sino de acumular pequeñas mejoras en compilación, memoria, planificación, comunicación entre GPUs y ejecución del modelo.
NVLink, NVFP4 y MTP elevan el throughput
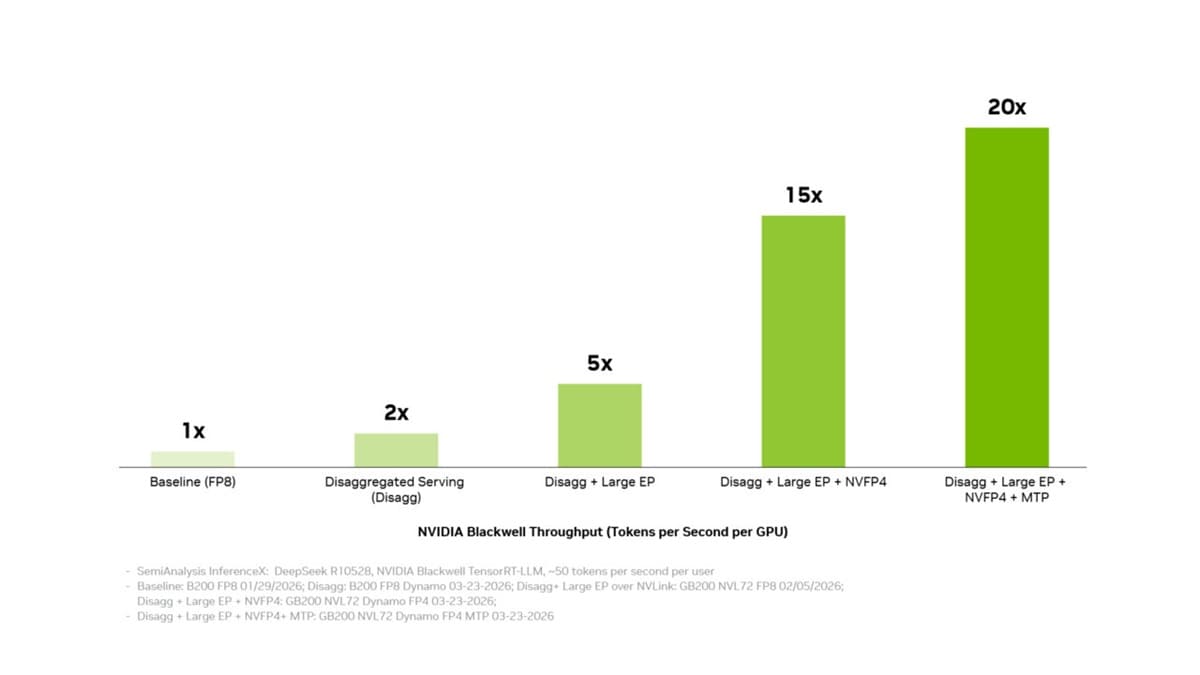
NVIDIA también atribuye parte del salto a tecnologías como NVLink, NVFP4 y Multi-Token Prediction (MTP). En conjunto, la compañía habla de hasta 20 veces más throughput frente a una base FP8 cuando se combinan desagregación, paralelismo experto grande, NVFP4 y MTP.
NVFP4 es especialmente importante para inferencia, porque permite reducir precisión y coste de memoria sin perder demasiado rendimiento útil en ciertos modelos. Menos bits por operación pueden traducirse en más tokens por segundo y menor consumo, siempre que el modelo mantenga calidad suficiente.
NVLink, por su parte, es clave en racks como GB300 NVL72, donde el modelo se reparte entre muchas GPUs. Cuanto más rápido se comunican aceleradores, menos tiempo se pierde moviendo activaciones, expertos, cachés y datos intermedios, algo crítico en modelos MoE grandes.
Los proveedores de inferencia ya aprovechan la mejora
NVIDIA cita a Baseten, Cognition, Deep Infra y Together AI como ejemplos de adopción. Baseten habría usado TensorRT-LLM para servir DeepSeek V4 Pro en Blackwell, mejorando tokens por segundo en cargas de razonamiento, código y contexto largo.
Deep Infra usa la pila de inferencia de NVIDIA para ejecutar modelos open-source frontier sobre Blackwell desde el primer día. Ese punto importa porque el tiempo hasta producción se ha convertido en una ventaja competitiva, especialmente cuando los modelos nuevos aparecen y los clientes quieren endpoints inmediatos.
Together AI también habría usado TensorRT-LLM sobre Blackwell para acelerar el salto de optimización a producción en experiencias de código en tiempo real como Cursor. En herramientas interactivas, bajar latencia y coste por token puede cambiar directamente la experiencia del usuario final.
NVIDIA refuerza su ventaja frente a aceleradores especializados
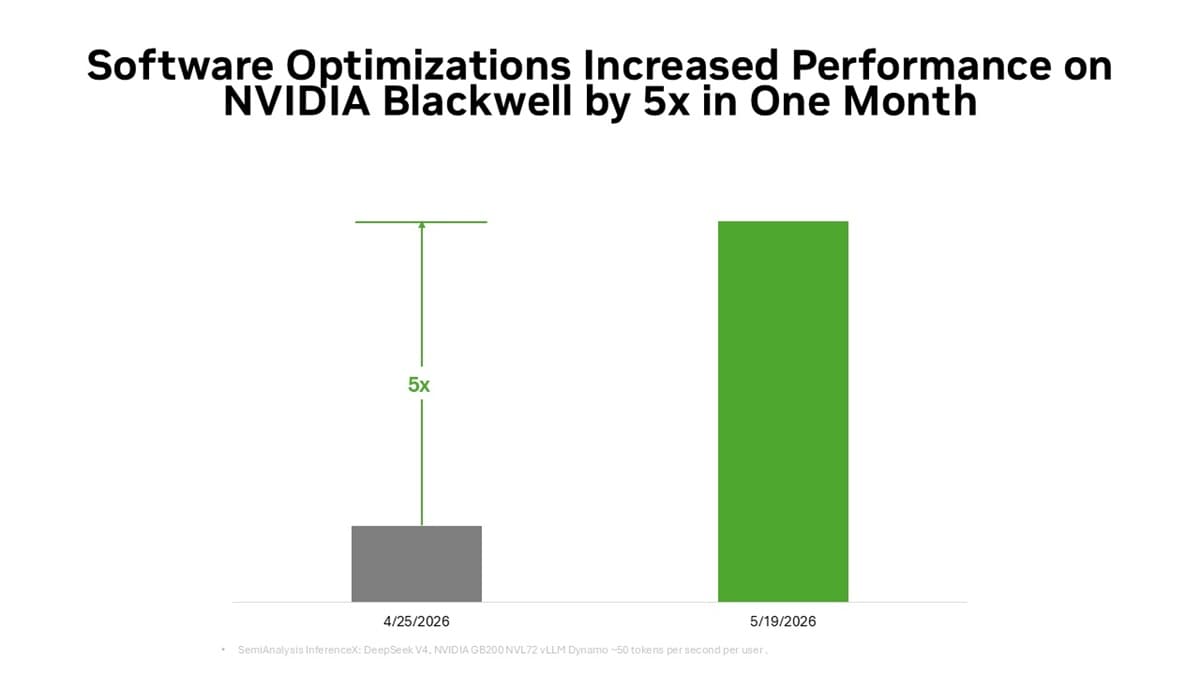
La lectura estratégica es clara: NVIDIA quiere demostrar que Blackwell no gana solo por ser potente, sino por mejorar continuamente después del despliegue. Reducir 5 veces el coste por token en un mes convierte el software en una extensión directa del hardware, y complica la comparación con rivales.
Esto afecta a startups de aceleradores de IA que prometen mejor eficiencia en cargas concretas. Si NVIDIA puede acercarse al coste de soluciones especializadas mediante software y mantener mejor ecosistema, disponibilidad y compatibilidad, su posición en inferencia sigue siendo muy difícil de atacar.
Aun así, la cifra debe leerse dentro del contexto de NVIDIA. Los 0,06$ por millón de tokens dependen del modelo, configuración, rack, carga, interactividad y optimizaciones concretas, por lo que no se puede extrapolar automáticamente a cualquier despliegue de IA.
La batalla de la IA se medirá en tokens por dólar
La conclusión es que la IA empresarial ya no solo comprará GPUs por capacidad bruta, sino por coste operativo real. Tokens por segundo, coste por millón de tokens, latencia y consumo serán métricas tan importantes como FLOPs, especialmente en razonamiento y agentes.
Blackwell sale reforzada porque NVIDIA puede vender una historia de mejora continua. GB200, GB300, TensorRT-LLM, Dynamo, NVLink, NVFP4 y MTP forman una plataforma integrada, capaz de bajar costes después del lanzamiento mediante optimización de software.
Para proveedores cloud y empresas que ejecutan modelos grandes, el mensaje es directo. Si DeepSeek V4 puede pasar de 0,30$ a 0,06$ por millón de tokens en un mes, la rentabilidad de Blackwell depende tanto del software como del silicio.
Vía: Wccftech










