Alibaba ha presentado el Zhenwu M890, su nuevo acelerador de IA orientado a inferencia avanzada y cargas de agentes, junto al modelo Qwen3.7-Max. La compañía refuerza una pila propia que combina silicio especializado, memoria HBM3 de alta capacidad, interconexión rápida y modelos de lenguaje, con una lectura claramente centrada en infraestructura.
El movimiento llega en pleno auge de la IA agéntica, donde ya no basta con ejecutar modelos grandes de forma puntual. Los nuevos sistemas necesitan sostener tareas largas, llamadas constantes a herramientas, baja latencia y gran concurrencia, justo el terreno donde Alibaba quiere colocar su nueva plataforma frente a rivales consolidados.
Zhenwu M890 mejora memoria, cálculo e interconexión frente al 810E
Got a close look at T-Head’s Zhenwu M890 at the Alibaba Cloud event in Hangzhou. 144 GB HBM. Training and inference on one chip. PCIe 5.0 x16. https://t.co/RwDwE3SCKt pic.twitter.com/IKns8uTzoS
— Poe Zhao (@poezhao0605) May 20, 2026
El Zhenwu M890 se basa en la arquitectura PPU propia de Alibaba, con un motor específico para cargas Transformer. El chip ofrece 0,6 PFLOPs en FP16, una cifra orientada a inferencia de alto rendimiento en centros de datos, con una posición que busca acercarse a aceleradores ya muy asentados.
Frente al Zhenwu 810E, el salto más visible está en la memoria. Alibaba pasa de 96 GB a 144 GB HBM3, un incremento del 50% que resulta clave para modelos con más contexto, más sesiones simultáneas y agentes con estados complejos, especialmente en despliegues empresariales de alta concurrencia.
La interconexión también sube de 700 GB/s a 800 GB/s, una mejora menos llamativa que la memoria, pero importante para sistemas densos. En inferencia agéntica, el cuello de botella no siempre está en el cálculo bruto, sino en mover datos entre aceleradores sin romper la latencia.
FP4, FP8 y FP16 buscan flexibilidad en inferencia moderna

El soporte para FP32, FP16, FP8 y FP4 deja claro que Alibaba quiere cubrir diferentes niveles de precisión dentro de la misma plataforma. En cargas modernas de IA, esa flexibilidad permite ajustar rendimiento, consumo y calidad de salida según el modelo, el tamaño del contexto o la fase de inferencia.
La presencia de FP4 para cargas de inferencia optimizadas resulta especialmente relevante en escenarios donde prima la eficiencia. No todas las tareas necesitan la misma precisión, y reducir formato puede mejorar densidad de cómputo si el software mantiene calidad de respuesta, estabilidad numérica y consistencia en producción real.
Este punto importa porque la batalla de los aceleradores ya no depende solo de grandes cifras. Un chip para agentes necesita competir en latencia, memoria útil, formatos de precisión y eficiencia por sesión, no únicamente en una prueba sintética de rendimiento pensada para enseñar músculo bruto.
ICN Switch 1.0 y Panjiu AL128 apuntan a infraestructura completa

Alibaba no presenta el M890 como una pieza aislada. El nuevo ICN Switch 1.0 alcanza 25,6 Tb/s y mantiene una latencia punto a punto inferior a 150 ns, dos cifras pensadas para sistemas donde muchos aceleradores deben comunicarse con rapidez, coherencia y baja penalización interna.
Ese chip de interconexión se combina con la CPU Yitian basada en Arm y las tarjetas de red Panmai dentro del servidor Panjiu AL128 Supernode. La idea es integrar 128 aceleradores de IA en un solo rack, con ancho de banda a escala PB/s para cargas muy paralelas.
La lectura técnica es clara: Alibaba quiere controlar no solo el acelerador, sino el nodo completo. Para agentes de IA, eso tiene sentido porque las cargas combinan modelo, memoria, red, llamadas a herramientas y ejecución persistente, una mezcla que exige coherencia entre hardware, software y capa de orquestación.
También hay una lectura industrial. La compañía afirma haber enviado alrededor de 560.000 chips Zhenwu hasta la fecha, con más de 400 clientes externos repartidos en 20 industrias. Si esa base sigue creciendo, Alibaba puede reforzar su nube con una infraestructura menos dependiente de aceleradores externos.
La hoja de ruta ya mira a V900 y J900

El Zhenwu M890 no será un producto aislado dentro de la familia. Alibaba ya trabaja en el Zhenwu V900, previsto para el tercer trimestre de 2027, con una arquitectura más evolucionada, 216 GB de memoria y 1.200 GB/s de interconexión para escalar cargas futuras.
Ese salto supondría otro incremento del 50% en memoria frente al M890 y una mejora del 50% en ancho de banda. Para modelos de agentes, esa dirección tiene lógica: más memoria para contexto y más interconexión para coordinar aceleradores en cargas distribuidas cada vez más exigentes.
Más adelante llegaría el Zhenwu J900, previsto para 2028, con una iteración arquitectónica más profunda. Todavía faltan detalles concretos, pero la hoja de ruta muestra que Alibaba quiere competir por continuidad, no solo presentar un chip puntual para cubrir una generación concreta.
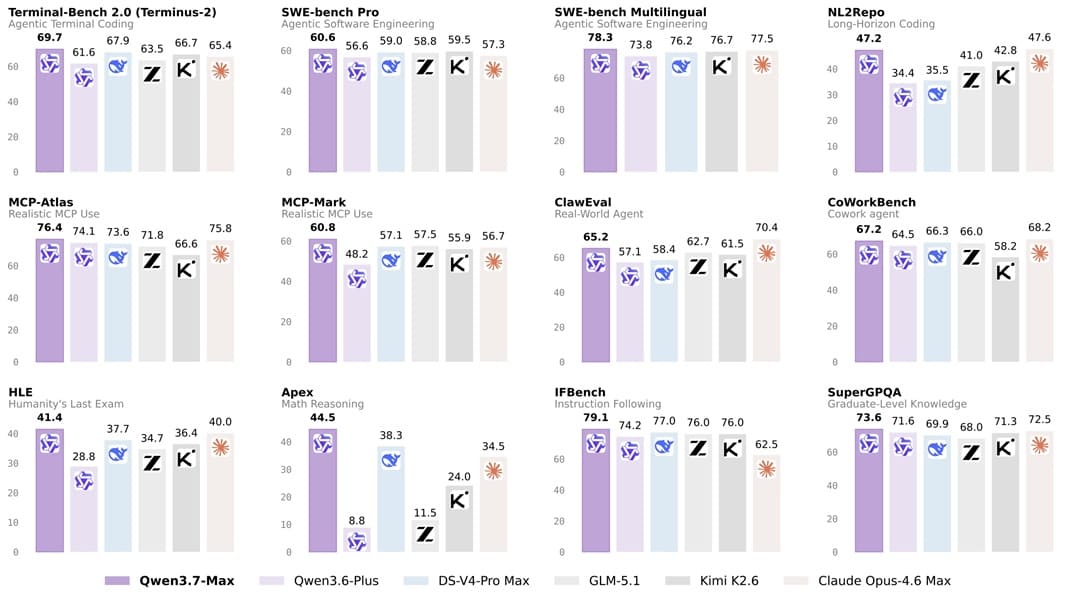
Qwen3.7-Max se centra en código, agentes y tareas largas

Junto al hardware, Alibaba también ha presentado Qwen3.7-Max, un modelo enfocado a programación avanzada, razonamiento complejo y ejecución prolongada de tareas. Su papel no parece limitado al chatbot convencional, sino a servir como base para sistemas de agentes más persistentes y flujos empresariales automatizados.
El dato más llamativo es su capacidad para sostener tareas agénticas de hasta 35 horas y gestionar más de 1.000 llamadas a herramientas sin degradación aparente. Esto resulta especialmente importante en automatización empresarial, desarrollo de software y flujos con acciones encadenadas durante largos periodos.
El modelo también llega optimizado para marcos como OpenClaw, Hermes Agent, Claude Code, Qwen Paw y Qoder. Esa compatibilidad refuerza su perfil como infraestructura para desarrolladores y empresas, no solo como modelo conversacional de uso general para tareas puntuales o asistencia básica.
En pruebas de código y agentes, Qwen3.7-Max aparece como una evolución directa frente a la generación anterior. Más allá de cada cifra, la lectura relevante está en el enfoque: Alibaba quiere unir modelo avanzado, herramientas de agente y hardware propio dentro de la misma estrategia.
Alibaba busca una pila propia frente a NVIDIA y Huawei
El lanzamiento del Zhenwu M890 y Qwen3.7-Max refleja una estrategia de integración vertical. Alibaba no quiere depender solo de GPU externas para IA, sino construir una pila completa con aceleradores, interconexión, CPU, red, supernodos y modelos de lenguaje integrados en su nube.
Ese control puede ser decisivo en China, donde el acceso a hardware internacional de alto rendimiento está cada vez más condicionado. Si Alibaba escala bien producción, software y compatibilidad, el M890 puede convertirse en una alternativa relevante para inferencia, agentes de IA y despliegues corporativos de gran volumen.
El reto seguirá estando en la ejecución real. Competir con NVIDIA, Huawei y futuras generaciones de aceleradores exige algo más que cifras prometedoras. Hace falta un ecosistema maduro, herramientas estables, eficiencia operativa y buen rendimiento sostenido en centros de datos reales, no solo presentaciones técnicas ambiciosas.
Con esta generación, Alibaba deja claro que la batalla de la IA ya no se libra solo en modelos. El futuro pasa por unir silicio especializado, memoria masiva, interconexión rápida y modelos capaces de ejecutar tareas largas, justo el terreno donde los agentes de IA empiezan a exigir infraestructura propia.
Vía: Wccftech