
OpenAI ha anunciado una alianza técnica con AMD, NVIDIA, Intel, Microsoft y Broadcom para atacar uno de los grandes problemas del entrenamiento de IA a gran escala: la comunicación entre GPU dentro de superordenadores. El resultado es MRC, Multipath Reliable Connection, un protocolo abierto orientado a redes de alto rendimiento.
El objetivo no pasa solo por aumentar velocidad, sino por mejorar resiliencia, continuidad operativa y eficiencia en grandes clusters de entrenamiento. En sistemas con decenas de miles de GPU, una transferencia retrasada puede dejar recursos inactivos y afectar al ritmo completo del entrenamiento de modelos avanzados.
MRC nace para evitar GPU esperando datos
We’ve partnered with @AMD, @Broadcom, @Intel, @Microsoft, and @NVIDIA, to release Multipath Reliable Connection (MRC), a new open networking protocol that helps large AI training clusters run faster and more reliably, with less wasted GPU time.https://t.co/AiV952AJXs
— OpenAI (@OpenAI) May 6, 2026
El problema que intenta resolver MRC aparece cuando enormes volúmenes de datos deben moverse entre GPU, CPU y sistemas de red durante entrenamientos distribuidos. OpenAI señala que la congestión de red, los fallos de enlace y los errores de dispositivos pueden provocar retrasos suficientes para frenar trabajos completos.
La clave del protocolo consiste en dividir una misma transferencia entre múltiples rutas paralelas, en lugar de depender de un único camino dentro del cluster. Con ello, la red puede esquivar fallos en microsegundos, repartir carga entre rutas disponibles y mantener mayor estabilidad durante cargas de entrenamiento masivo.
Un estándar abierto para toda la industria de IA
OpenAI ha liberado MRC a través del Open Compute Project, lo que permite que otras compañías puedan estudiar, implementar y adaptar el protocolo en futuras plataformas de IA. La especificación recoge trabajo conjunto con AMD, Broadcom, Intel, Microsoft y NVIDIA, reforzando su enfoque como estándar colaborativo.
Este punto resulta especialmente importante porque la IA a gran escala ya no depende únicamente de GPU más potentes. La infraestructura necesita redes capaces de sostener comunicación constante entre miles de aceleradores, evitando que almacenamiento, interconexión o congestión interna terminen limitando el rendimiento real del sistema.
El cambio clave está en dividir enlaces de 800 Gb/s
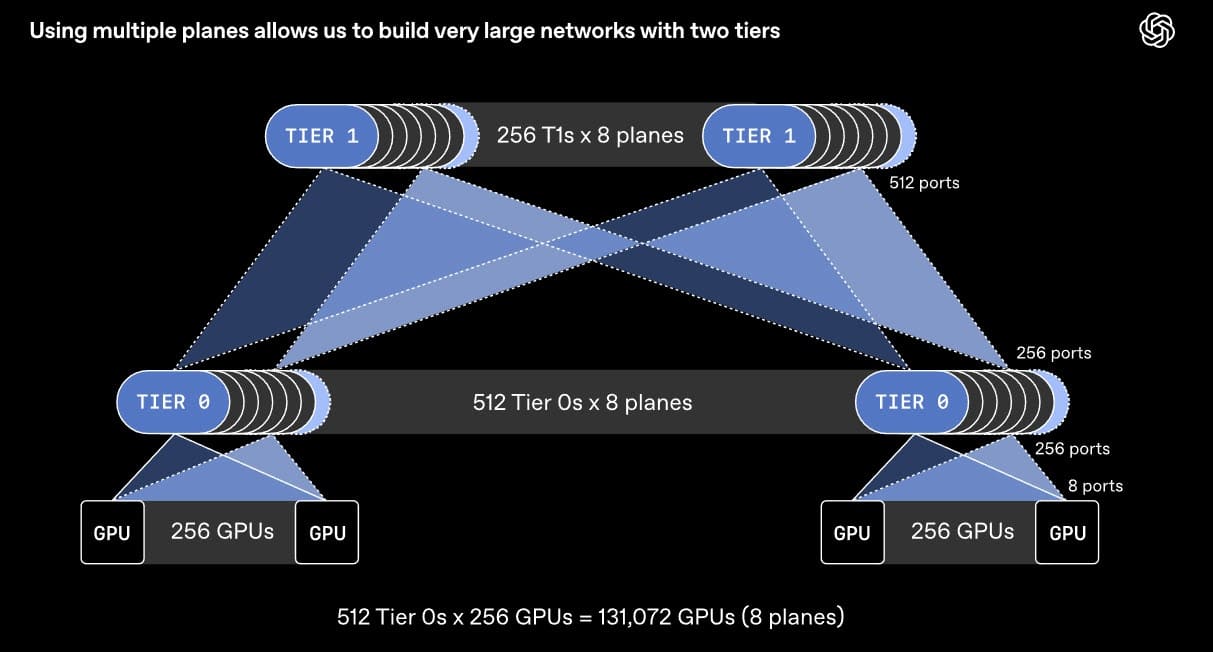
OpenAI explica que, en lugar de tratar una interfaz como un único enlace de 800 Gb/s, MRC permite dividirla en varios enlaces más pequeños. Por ejemplo, una interfaz podría conectarse a ocho switches diferentes, creando varios planos paralelos de 100 Gb/s para repartir mejor el tráfico.
Este enfoque cambia de forma profunda el diseño del cluster. Según la compañía, un switch con 64 puertos de 800 Gb/s podría reorganizarse como una red con 512 puertos de 100 Gb/s, permitiendo conectar alrededor de 131.000 GPU con solo dos niveles de switches.
La lectura técnica es clara: MRC no busca únicamente más ancho de banda bruto, sino una topología más flexible, tolerante a fallos y menos dependiente de rutas únicas. En entrenamientos de IA a gran escala, esa diferencia puede ser crítica para mantener GPU ocupadas y reducir pérdidas de eficiencia.
MRC amplía RDMA sobre RoCE para supercomputación
El nuevo protocolo amplía el modelo RDMA sobre RoCE, una tecnología utilizada para acceso directo a memoria remota acelerado por hardware sobre redes Ethernet convergentes. En la práctica, esto permite que GPU y CPU intercambien datos con menor intervención del sistema, reduciendo latencias en cargas distribuidas.
La mejora está en añadir soporte multipath, control de congestión, seguimiento de salud de rutas y recuperación ante fallos sobre una base ya conocida por la industria. De este modo, OpenAI intenta evitar una ruptura completa con infraestructuras existentes, facilitando una adopción más sencilla en futuros superordenadores de IA.
GB200 Blackwell ya utiliza el protocolo
OpenAI afirma que MRC ya se ha desplegado en superordenadores con GPU NVIDIA GB200 Blackwell, utilizados para entrenar modelos frontera. Entre las infraestructuras mencionadas aparecen Oracle Cloud Infrastructure en Abilene, Texas, además de los superordenadores Fairwater de Microsoft.
La compañía también indica que el protocolo ya se ha usado para entrenar varios modelos sobre hardware de NVIDIA y Broadcom. Este detalle refuerza la idea de que MRC no es una simple propuesta teórica, sino una tecnología de red ya integrada en plataformas reales de entrenamiento avanzado.

Stargate necesitará redes más resistentes
El protocolo también tendrá un papel relevante en Stargate, el gran superordenador de OpenAI construido por Oracle Cloud Infrastructure en Abilene. La infraestructura apunta a desplegar 10 GW de capacidad de cómputo para IA en 2029, una escala que exige redes mucho más resistentes que las usadas en clusters tradicionales.
Con MRC disponible para toda la industria, OpenAI intenta impulsar un estándar común para resolver uno de los problemas más complejos del entrenamiento de IA: escalar GPU, redes y almacenamiento sin que la comunicación interna frene el conjunto. La alianza con AMD, NVIDIA, Intel, Microsoft y Broadcom refuerza precisamente esa lectura.
La conclusión de fondo es que la próxima carrera de IA no se jugará solo en aceleradores más rápidos. También dependerá de interconexiones capaces de mantener miles de GPU trabajando al mismo tiempo, con rutas redundantes, menor latencia y una arquitectura de red preparada para superordenadores cada vez más grandes.
Vía: Wccftech










