Tensordyne ha anunciado el tape-out de Napier, su nuevo chip de IA fabricado en 3 nm de TSMC y orientado a inferencia. La compañía asegura que su plataforma puede superar a NVIDIA Blackwell y plantar cara a Rubin, aunque las comparativas proceden del propio fabricante y requieren validación externa.
El chip será la base del sistema Tensordyne Napier TDN, desarrollado junto a Broadcom y HPE Juniper Networks. La propuesta combina matemáticas logarítmicas, memoria integrada y una interconexión propietaria para escalado interno, con el objetivo de aumentar tokens por vatio sin disparar el coste eléctrico del centro de datos.
Napier se centra en inferencia, no solo en potencia bruta


Napier no intenta competir únicamente en cifras máximas de cálculo. Su enfoque está en inferencia, donde pesan latencia, coste por token, ocupación del hardware y eficiencia energética. En ese escenario, la métrica clave no es el pico de FLOPS, sino cuántos tokens genera cada vatio consumido.
El chip integra 138.000 millones de transistores, 144 GB de HBM3E, 256 MB de SRAM y alcanza 2,1 PFLOPS FP8 con un TDP de 300 W. Sobre el papel es una configuración muy agresiva, pero el verdadero examen estará en cargas sostenidas con modelos grandes y tráfico real.
Tensordyne afirma que ya trabaja en despliegues beta y en una demanda prevista superior a 200 millones de dólares para sistemas Napier. Ese dato sugiere interés comercial, aunque todavía falta comprobar si la plataforma puede traducir sus promesas en ahorro operativo medible para clientes de IA.
La arquitectura combina matemáticas logarítmicas, memoria y comunicación interna
La primera pieza diferencial es TDN Math, una capa basada en matemáticas logarítmicas que sustituye operaciones masivas de multiplicación por cómputo simplificado basado en sumas. Si el planteamiento escala bien, Napier podría mejorar la eficiencia al reducir una de las operaciones más repetidas en inferencia.
El segundo pilar es TDN AIP, el procesador de IA que combina SRAM rápida con HBM3E para reducir ciclos muertos. Esta integración resulta importante porque, en modelos grandes, un acelerador pierde eficiencia si pasa demasiado tiempo esperando datos en lugar de ejecutar operaciones útiles.
El tercer elemento es TDN Link, una interconexión propietaria para escalado interno con latencia submicrosegundo entre procesadores. Aquí Tensordyne busca evitar cuellos de botella al escalar varios chips dentro del mismo sistema, porque la eficiencia por chip pierde valor si la comunicación interna limita el rendimiento del conjunto.
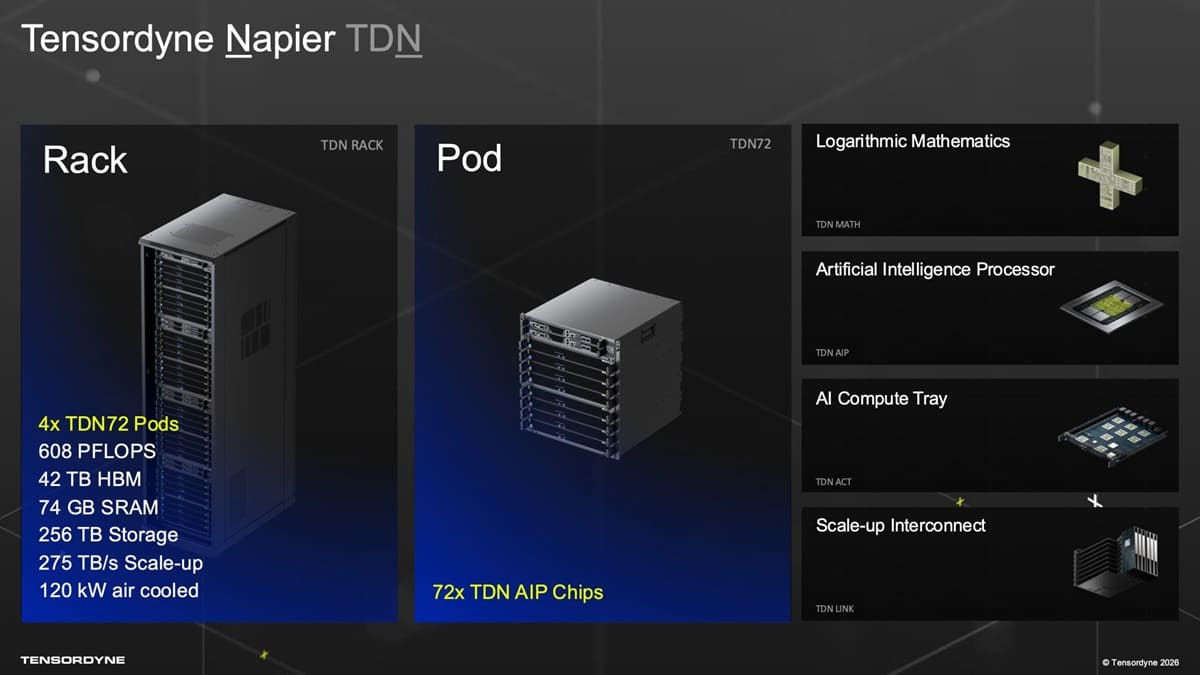

El rack TDN72 concentra memoria y cómputo para modelos gigantes
La plataforma se agrupa en sistemas TDN72, con 72 chips Napier por servidor. Un rack completo combinaría cuatro pods, hasta 288 chips, 608 PFLOPS FP8, 74 GB de SRAM, 42 TB de HBM3E y un consumo nominal de 120 kW, manteniendo refrigeración por aire.
Tensordyne compara esta configuración con racks NVIDIA NVL72 basados en Blackwell o Rubin. Según la compañía, Napier ofrecería 17 veces más tokens por vatio y 13 veces más tokens por segundo frente a Blackwell, además de hasta 33 millones de dólares más de ingresos anuales por rack.
La cautela aquí es obligatoria. Las cifras dependen del modelo, precisión, ocupación, precio por token y escenario de despliegue. Aun así, el mensaje de fondo es que la inferencia empieza a medirse por coste operativo total, no solo por rendimiento máximo de GPU.


Rubin sigue siendo el rival más difícil de batir
Tensordyne también apunta contra NVIDIA Rubin, todavía pendiente de despliegue masivo. La compañía sostiene que un solo rack Napier podría servir modelos de varios billones de parámetros con 1.000 tokens/s por usuario, mientras una solución alternativa necesitaría varios racks combinando Rubin y otros sistemas.
El problema para cualquier nuevo actor no está solo en el silicio. NVIDIA mantiene ventaja en CUDA, bibliotecas, redes, servidores certificados y adopción empresarial. Por eso, Napier deberá demostrar eficiencia, compatibilidad de software y facilidad de despliegue antes de considerarse una amenaza directa para NVIDIA.
La lectura prudente es que Napier representa una arquitectura muy ambiciosa para inferencia, no una derrota inmediata de Blackwell o Rubin. Si las cifras se sostienen fuera de sus propias pruebas, Tensordyne podría ganar espacio donde el coste por token importa más que la flexibilidad general de una GPU.
Vía: Wccftech