
SanDisk está explorando nuevas vías para aliviar uno de los grandes límites de la IA: la memoria. Su propuesta combina NAND Flash de alta capacidad, encapsulado 3D y memoria HBM en el mismo interposer, buscando acercar grandes volúmenes de datos al chip sin depender solo de DRAM avanzada.
La idea aparece en la patente US 12,430,274 B2, donde SanDisk describe un procesador, GPU o acelerador de IA integrado directamente sobre un tile NAND con tecnología CBA, acompañado por pilas HBM alrededor del interposer. Es una arquitectura pensada para reducir el movimiento de datos entre cómputo, memoria y almacenamiento.
La IA está llevando HBM a un límite complicado
HBM se ha convertido en la memoria crítica para aceleradores de IA, pero su éxito también ha creado un problema. Cada nueva GPU necesita más ancho de banda, más capacidad y más pilas HBM, justo cuando la demanda de centros de datos presiona precios, suministro y disponibilidad.
El límite no es solo económico. HBM ofrece muchísimo ancho de banda, pero su capacidad por pila sigue siendo relativamente reducida frente a NAND. Para modelos de IA, bases vectoriales o inferencia con contextos enormes, la capacidad disponible cerca del acelerador empieza a ser tan importante como la velocidad pura.
Ahí aparece el cuello de botella de memoria: el cómputo crece más rápido que la memoria capaz de alimentarlo. Si los datos deben viajar desde SSD, RAM del sistema o almacenamiento remoto, la GPU queda esperando. SanDisk intenta atacar ese problema acercando memoria no volátil de gran capacidad al encapsulado del acelerador.
HBF intenta acercar la NAND al modelo de HBM
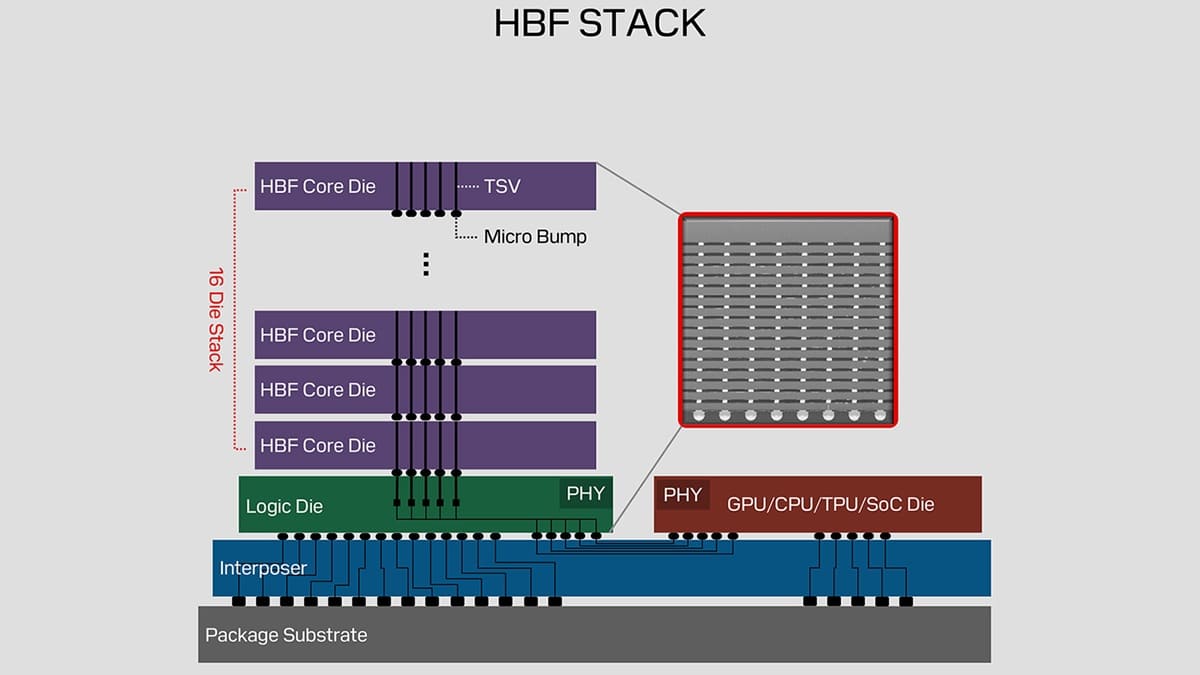
High-Bandwidth Flash parte de una idea sencilla, pero muy ambiciosa: usar NAND, mucho más densa y barata que DRAM, con una jerarquía de encapsulado inspirada en HBM. En lugar de tratar la NAND como almacenamiento lejano, SanDisk quiere convertirla en una capa de memoria de alta capacidad junto al acelerador.
La arquitectura HBF apila capas de NAND conectadas mediante vías TSV y lógica dedicada, buscando más paralelismo interno y menor distancia física con el die de cómputo. Según SanDisk, el objetivo es ofrecer capacidades de hasta 4 TB por stack, muy por encima de lo habitual en HBM.
Esto no significa que HBF sustituya a HBM en todo. La NAND sigue teniendo más latencia que DRAM, así que su papel natural sería servir como memoria de gran capacidad para datos menos inmediatos. La clave está en combinar capacidad masiva con ancho de banda suficiente para IA, no en reemplazar cada acceso de HBM.
La patente va más allá al colocar NAND bajo el die de cómputo
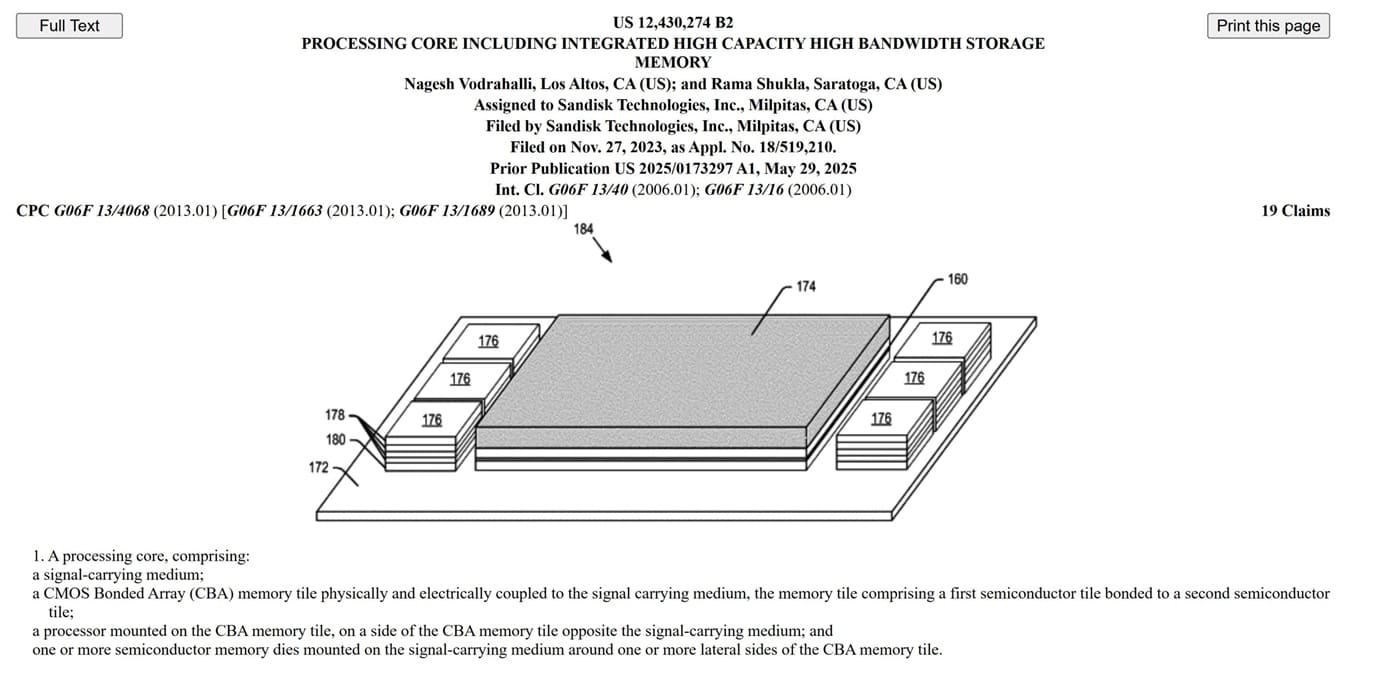
La nueva patente de SanDisk resulta interesante porque no se limita a colocar HBF junto a la GPU. Explora una arquitectura donde un tile NAND con CBA queda directamente bajo el die de cómputo, creando una integración vertical más agresiva entre procesador y memoria no volátil.
CBA, o CMOS Bonded Array, permite unir el array NAND con la lógica CMOS de forma más eficiente. En este contexto, SanDisk plantea un tile NAND de alta capacidad acoplado a lógica de control, situado bajo un procesador multinúcleo, GPU, TPU, SoC o acelerador de IA.
El diseño también mantiene pilas HBM alrededor del conjunto en el interposer, lo que confirma una idea importante: SanDisk no propone eliminar HBM, sino usarla para los accesos más urgentes. La NAND integrada actuaría como una memoria amplia para lecturas, escrituras y conjuntos de datos mucho más grandes.
La lectura estratégica es clara. Si la NAND puede acercarse físicamente al acelerador, se reducen viajes a almacenamiento externo, RAM del sistema o buses más lentos. Para IA, eso puede traducirse en menos movimiento de datos, menor consumo energético y mejor aprovechamiento del silicio de GPU.
HBM y NAND cumplirían funciones distintas
La clave de esta arquitectura está en repartir tareas. HBM seguiría encargándose de datos calientes, accesos inmediatos y operaciones sensibles a latencia, donde la DRAM apilada mantiene ventaja. La NAND, en cambio, serviría para almacenar volúmenes mucho mayores de parámetros, vectores o datos de inferencia.
Este enfoque tiene sentido en IA moderna. Muchas cargas no necesitan que todos los datos estén en HBM todo el tiempo, pero sí requieren acceso rápido a conjuntos enormes. Una NAND cercana al die podría actuar como capa intermedia entre HBM y almacenamiento tradicional, reduciendo dependencias externas.
El gran atractivo está en el coste por capacidad. NAND permite escalar a terabytes de forma más viable que DRAM, aunque con menor velocidad. Si SanDisk logra equilibrar ancho de banda, latencia y consumo, HBF podría convertirse en una solución complementaria para aceleradores de IA centrados en inferencia.
La integración vertical también trae problemas difíciles
El concepto es potente, pero no está listo para convertirse mañana en producto comercial. Apilar NAND bajo un acelerador plantea desafíos en temperatura, alimentación, rendimiento de fabricación y coste del encapsulado, especialmente si el diseño también integra HBM en el mismo interposer.
El calor es una de las grandes dudas. Una GPU o acelerador de IA puede consumir cientos de vatios, mientras la NAND necesita mantener fiabilidad y retención de datos. Colocar memoria bajo el die principal obliga a resolver disipación térmica sin comprometer estabilidad ni vida útil de la memoria.
También está el problema económico. Un encapsulado con GPU, HBM, NAND CBA, interposer avanzado y rutas verticales complejas no será barato. La ventaja tendría que compensar el coste mediante más capacidad local, menos movimiento de datos y mejor rendimiento por vatio en inferencia.
Por eso conviene leer la patente como mapa estratégico, no como hoja de producto inmediata. SanDisk está protegiendo una arquitectura que podría ser clave, pero todavía faltan validación, estandarización, socios de silicio y adopción real. En semiconductores, una patente fuerte no garantiza una implementación industrial cercana.
Fuente de la imagen: US Patents
La batalla de la memoria ya no será solo DRAM contra NAND
El movimiento de SanDisk encaja con una tendencia mayor: la memoria para IA se está diversificando. HBM, LPDDR, CXL, SSD, HBF y nuevas capas de memoria intentan cubrir huecos distintos. El objetivo ya no es elegir una sola tecnología, sino construir jerarquías de memoria más cercanas al acelerador.
Esto puede cambiar la forma en que se diseñan GPUs, TPUs y aceleradores personalizados. En vez de depender únicamente de HBM carísima, los fabricantes podrían combinar DRAM ultrarrápida, NAND de alta capacidad y enlaces internos más anchos, adaptando cada capa al tipo de dato y latencia requerida.
Para SanDisk, la oportunidad está en llevar NAND más allá del SSD. Si HBF gana tracción, la compañía podría colocarse en una zona mucho más estratégica del centro de datos de IA. No vendería solo almacenamiento, sino una pieza directa del encapsulado de cómputo avanzado.
HBF apunta primero a inferencia, no a sustituir todo el ecosistema
La aplicación más lógica está en inferencia de IA, donde muchos modelos necesitan manejar contextos largos, bases de conocimiento, vectores o datos persistentes. En esos escenarios, tener NAND de alto ancho de banda cerca del acelerador puede reducir latencia de acceso frente a SSD externos y presión sobre HBM.
En entrenamiento, HBM seguirá siendo esencial por su latencia y ancho de banda extremos. Pero en inferencia, donde el coste por consulta, la capacidad local y la eficiencia importan muchísimo, HBF puede tener más sentido. La propuesta apunta a más memoria efectiva sin multiplicar pilas HBM caras y escasas.
La conclusión es clara: SanDisk no está planteando una simple NAND más rápida, sino una nueva capa de memoria para IA. Si logra pasar de patente a producto, HBF podría ayudar a diseñar aceleradores con más capacidad local, menos dependencia de HBM y menor movimiento de datos fuera del encapsulado.
Vía: Wccftech










