
Qualcomm ha presentado Dragonfly como una plataforma completa para centros de datos de IA, reuniendo bajo una misma marca CPUs, aceleradores, memoria avanzada, conectividad y silicio personalizado. La compañía ya no plantea componentes aislados, sino una infraestructura completa para IA agéntica y computación a escala de rack.
El movimiento amplía lo visto con Dragonfly C1000 y HBC, situando a Qualcomm en una zona mucho más ambiciosa del mercado. La estrategia pasa por atacar rendimiento por vatio, movimiento de datos y coste total de propiedad, tres factores que empiezan a definir la próxima generación de centros de datos.
Dragonfly deja de ser una marca aislada y pasa a ser un ecosistema completo
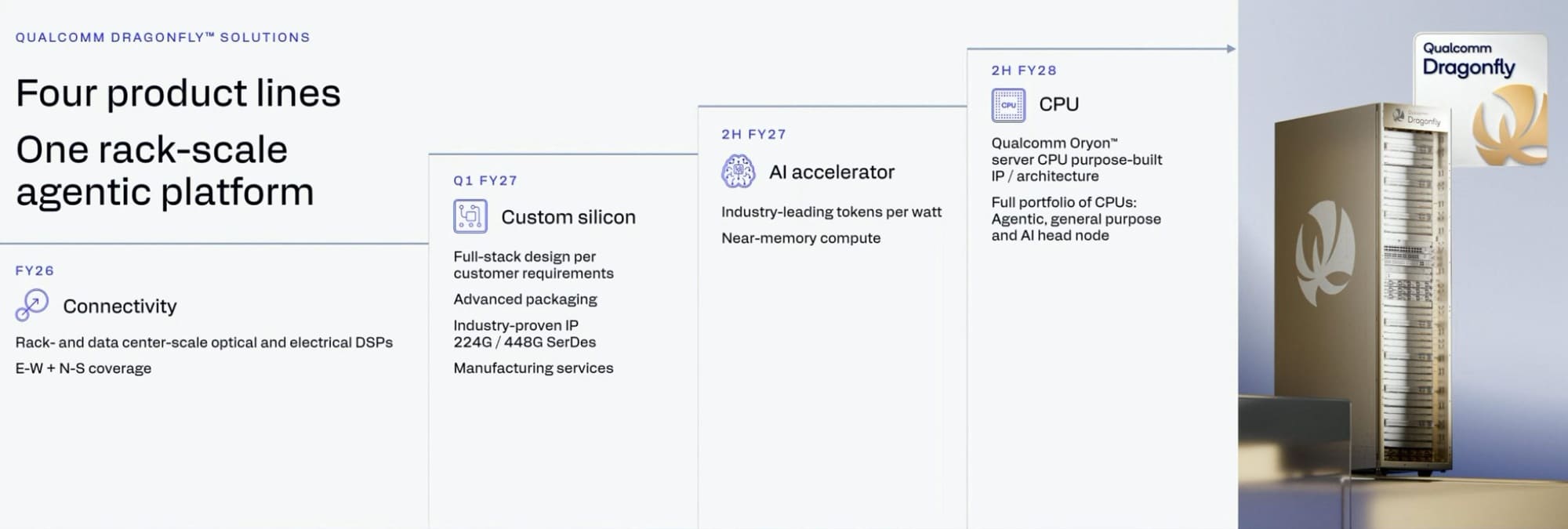

La clave del anuncio está en que Qualcomm Dragonfly no nace como una sola CPU ni como un único acelerador de IA, sino como una familia coordinada de productos. La plataforma incluye Dragonfly C1000, aceleradores AI200, AI250 y AI300, conectividad avanzada, tecnología HBC y servicios de silicio personalizado.
Ese enfoque resulta importante porque la IA moderna ya no escala solo añadiendo más GPU. Los centros de datos necesitan CPU, memoria, red y aceleradores trabajando como una plataforma unificada, especialmente cuando las cargas agénticas exigen baja latencia, contexto persistente y mucha transferencia de datos entre nodos.
Qualcomm intenta trasladar al servidor una ventaja que domina desde hace años en otros segmentos: eficiencia energética con integración de sistema. La lectura técnica es que Dragonfly busca competir más por rendimiento, por vatio y economía por token que por fuerza bruta aislada, una métrica cada vez más crítica en inferencia.
AI300 será el acelerador más avanzado de la hoja de ruta


El Qualcomm Dragonfly AI300 aparece como la tercera generación de la familia de aceleradores de IA, tras AI200 y AI250. Según la hoja de ruta oficial, AI300 será una plataforma de inferencia a escala de rack con refrigeración por aire y líquida directa, pensada para despliegues de alta densidad en 2028.
La gran diferencia estará en HBC Gen 2, una evolución de la tecnología High Bandwidth Compute que Qualcomm ya asocia al AI250 mediante HBC Gen 1. El objetivo es romper el cuello de botella de memoria, integrando computación y ancho de banda efectivo en una solución más eficiente para modelos grandes.
Qualcomm afirma que AI300 con HBC Gen 2 multiplicará por 54 el ancho de banda efectivo frente a AI200, mientras que AI250 con HBC Gen 1 apunta a un salto de 18 veces. El dato es agresivo, aunque conviene tratarlo como estimación de arquitectura hasta ver sistemas reales y pruebas externas.
La compañía también habla de una mejora de 4 a 8 veces en rendimiento por vatio frente a arquitecturas GPU actuales en métricas vinculadas al ancho de banda de memoria por tarjeta. Si esa eficiencia se confirma, Dragonfly podría ser especialmente competitivo en inferencia LLM, modelos multimodales y agentes persistentes.
HBC es la pieza que Qualcomm quiere usar contra la memoria tradicional

La tecnología High Bandwidth Compute es una de las partes más importantes de Dragonfly. Qualcomm la presenta como una arquitectura de computación cercana a memoria, con integración 3D, orientada a reducir el coste energético del movimiento de datos. El planteamiento ataca uno de los problemas estructurales de la IA: alimentar los aceleradores sin disparar consumo y latencia.
Frente a una visión centrada únicamente en HBM, Qualcomm intenta diferenciarse con capacidad y eficiencia. La firma asegura que HBC Gen 1 en AI250 permitirá 133 TB/s por tarjeta, con un aumento de 18 veces frente a AI200 basado en LPDDR5X. Esa cifra explica por qué Dragonfly no se entiende sin su memoria asociada.
La lectura de fondo es clara: la batalla de la IA no se gana solo con más cálculo, sino con más datos llegando a tiempo al motor de inferencia. En cargas agénticas, donde hay razonamiento continuo, contexto y múltiples llamadas encadenadas, la memoria puede pesar tanto como el acelerador.
Conectividad óptica, cobre y SerDes para escalar más allá del rack


Qualcomm también quiere entrar en la parte menos vistosa, pero más decisiva, del centro de datos: la conectividad. Dragonfly cubrirá enlaces die-to-die, cobre, óptica y campus, con soluciones SerDes, PAM4, DSP coherent-lite y telemetría. El objetivo es reducir cuellos de botella en infraestructuras distribuidas y desagregadas.
La hoja de ruta incluye conectividad 800G y 1.6T, con alcance desde enlaces internos hasta despliegues de campus de hasta 20 km. Esta parte es clave porque la IA a gran escala depende cada vez más de mover datos entre racks, aceleradores y almacenamiento con mínima pérdida de eficiencia.
El anuncio también menciona tecnologías como la óptica coempaquetada (CPO) y soluciones ópticas integradas en el paquete de red. Ambos enfoques buscan acercar la conectividad óptica al silicio principal para reducir consumo, latencia y pérdidas de señal, un punto crítico cuando el tráfico entre aceleradores se dispara.
El silicio personalizado abre otra vía frente a hyperscalers y cloud

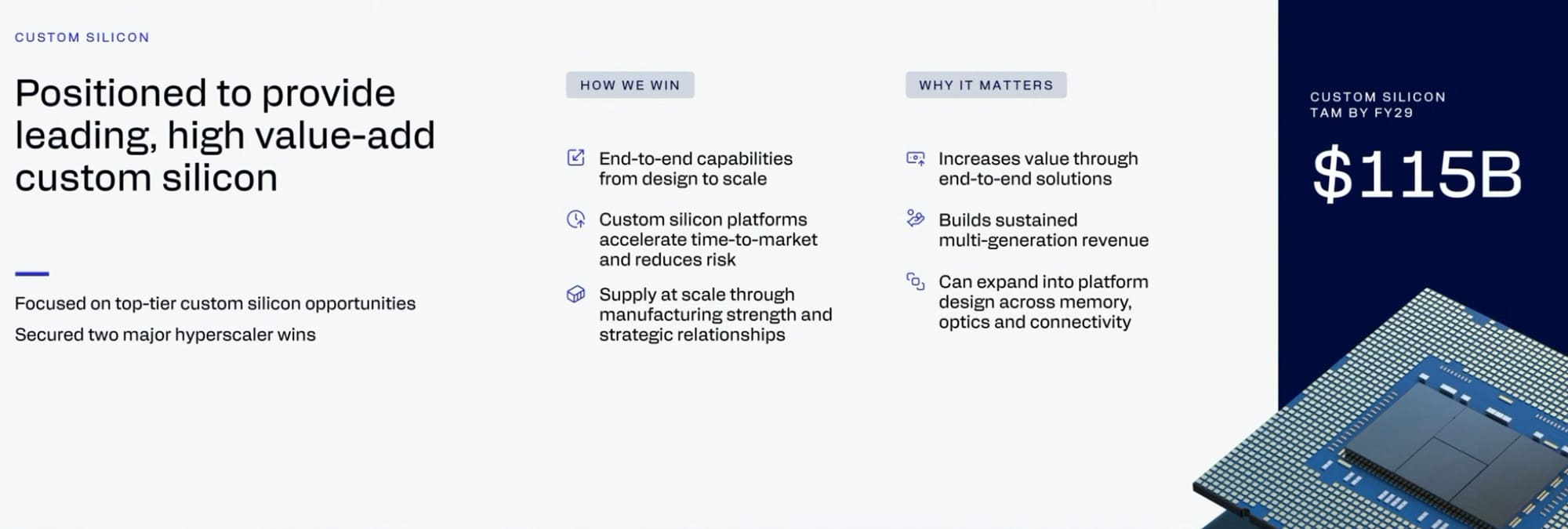
Además de CPUs y aceleradores, Qualcomm ofrecerá silicio personalizado para clientes que necesiten diseños específicos de IA, nube o infraestructura. La compañía habla de co-diseño de extremo a extremo, IP propia, encapsulado avanzado y ejecución hasta fabricación en volumen. Es una oferta pensada para hyperscalers que buscan diferenciar hardware, coste y consumo.
Este movimiento tiene lógica estratégica. Los grandes clientes cloud ya no compran siempre productos estándar, sino que buscan chips adaptados a sus cargas, software y centros de datos. Qualcomm intenta colocarse como socio de diseño, no solo como proveedor de componentes, aprovechando su experiencia en integración y bajo consumo.
La parte delicada está en la ejecución. Diseñar silicio personalizado para centros de datos exige plazos largos, validación dura, cadenas de suministro estables y soporte técnico profundo. Qualcomm tiene propiedad intelectual y experiencia de fabricación, pero debe demostrar que puede sostener proyectos de servidor con exigencias hiperescala.
Qualcomm entra en IA de centro de datos por la vía más difícil
Dragonfly supone una entrada ambiciosa porque Qualcomm no se limita a lanzar un acelerador para competir con GPU. La compañía intenta construir una pila completa con CPU, aceleradores de inferencia, memoria HBC, conectividad, software y silicio personalizado, justo donde los grandes clientes valoran integración y coste total.
El problema es que llega a un mercado extremadamente competido. NVIDIA domina el ecosistema de IA, AMD está empujando Instinct y EPYC, Intel sigue defendiendo Xeon y aceleradores, mientras los hyperscalers desarrollan chips propios. Dragonfly tendrá que competir contra plataformas maduras, no contra productos aislados.
Aun así, el enfoque tiene sentido si Qualcomm logra diferenciarse en inferencia. La IA agéntica dispara la demanda de tokens, memoria, conectividad y eficiencia por vatio, una combinación donde su experiencia histórica en bajo consumo puede tener valor real. La cuestión será si esa ventaja llega a tiempo y con suficiente soporte software.
La lectura final es que Qualcomm Dragonfly convierte la apuesta de la compañía por centros de datos en una estrategia de plataforma completa. No basta con prometer más eficiencia: deberá demostrar rendimiento sostenido, integración real y adopción comercial. Pero por primera vez, Qualcomm parece entrar en IA de servidor con una propuesta de pila completa.
Vía: Wccftech










