Google ha presentado la nueva familia de modelos Gemma 4, una generación de modelos open-source de IA diseñada para ejecutarse de forma eficiente en hardware local, incluyendo GPUs NVIDIA RTX de consumo. En colaboración con NVIDIA, esta nueva serie se optimiza específicamente para aprovechar Tensor Cores y el ecosistema CUDA, lo que permite ejecutar cargas de trabajo de IA agentica con baja latencia directamente en PCs y estaciones de trabajo.
Este movimiento refuerza una tendencia clara dentro del sector de IA, donde los modelos dejan de depender exclusivamente de la nube para ejecutarse en dispositivos locales. La clave está en la capacidad de procesar contexto en tiempo real, algo fundamental para asistentes inteligentes, automatización avanzada y flujos de trabajo personalizados.
Gemma 4: modelos compactos diseñados para ejecución local eficiente
La familia Gemma 4 incluye variantes como E2B, E4B, 26B y 31B, cubriendo desde escenarios de edge computing hasta entornos de alto rendimiento. Los modelos más ligeros, como E2B y E4B, están orientados a inferencia de baja latencia, permitiendo ejecución completamente offline incluso en dispositivos como Jetson Orin Nano.
Por su parte, los modelos 26B y 31B se enfocan en tareas más complejas, como razonamiento avanzado, generación de código o automatización mediante agentes. Esta segmentación permite adaptar el modelo a distintos entornos sin perder eficiencia, algo clave en la adopción de IA local.
IA multimodal, agentes y soporte para múltiples idiomas
Uno de los pilares de Gemma 4 es su capacidad multimodal, con soporte para texto, imagen, vídeo y audio, lo que habilita casos de uso más avanzados en análisis de contenido y automatización. Además, incorpora function calling nativo, facilitando el desarrollo de agentes autónomos capaces de interactuar con herramientas externas.
El modelo también destaca por su soporte multilingüe, con compatibilidad para más de 35 idiomas y entrenamiento en más de 140 idiomas, lo que amplía su alcance en aplicaciones globales. Este enfoque convierte a Gemma 4 en una solución versátil dentro del ecosistema de IA generativa.
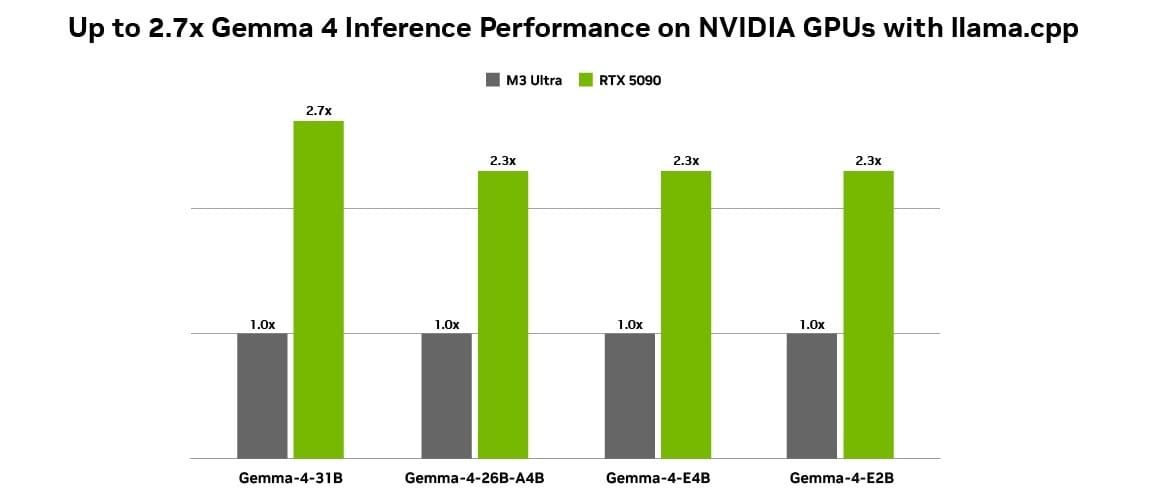
Integración con RTX, DGX Spark y herramientas de desarrollo
La optimización para GPUs NVIDIA RTX permite ejecutar estos modelos con mayor eficiencia, aprovechando la aceleración de Tensor Cores para mejorar el rendimiento en tareas de inferencia. Además, Gemma 4 también es compatible con sistemas como DGX Spark y módulos Jetson, cubriendo desde edge hasta entornos profesionales.
Para facilitar el despliegue, NVIDIA ha colaborado con herramientas como Ollama, llama.cpp y Unsloth, permitiendo ejecutar, ajustar y desplegar modelos de forma local. Esta integración reduce la barrera de entrada para desarrolladores que buscan implementar IA agentica en local.
El avance de la IA local y su impacto en el ecosistema
La llegada de Gemma 4 optimizado para RTX refuerza el crecimiento de la IA en dispositivos locales, donde soluciones como asistentes persistentes o automatización avanzada empiezan a ganar protagonismo. Aplicaciones como OpenClaw ya permiten ejecutar agentes que interactúan con archivos, aplicaciones y flujos de trabajo en tiempo real.
Este enfoque introduce un cambio relevante en el ecosistema: la capacidad de ejecutar modelos avanzados sin depender de la nube mejora la privacidad, reduce latencias y abre nuevas posibilidades para el usuario. En este contexto, la combinación de hardware NVIDIA y modelos open-source marca un paso clave hacia una IA más accesible y distribuida.
Vía: Wccftech