
La startup Taalas asegura haber encontrado una vía alternativa para reducir la latencia en LLM y mejorar el rendimiento por token: convertir modelos de IA en silicio dedicado mediante un enfoque de ASIC específico por modelo. Su primer producto, el HC1, integra Llama 3.1 8B directamente en hardware y, según la compañía, logra 10× más tokens por segundo (TPS) y 20× menor coste de producción frente a infraestructuras de gama alta tradicionales.
El planteamiento rompe con el paradigma de cómputo generalista con GPU y se alinea con la idea de especializar cargas de IA a nivel físico, eliminando capas intermedias de software y reduciendo el tráfico de datos que penaliza la latencia.
“Hardwire” del modelo y fusión de almacenamiento y cómputo
La propuesta de Taalas se apoya en dos pilares. Primero, el mapeo directo de redes neuronales al silicio, optimizando cada bloque para un modelo concreto. Segundo, la fusión de almacenamiento y computación, con el objetivo de superar la llamada pared de memoria y minimizar la sobrecarga de comunicación interna.
Según la empresa, todo el cálculo ocurre con una densidad a nivel DRAM, evitando dependencias de HBM, refrigeración avanzada o empaquetado complejo. El resultado es un flujo de datos más corto y predecible, clave para mejorar el tiempo de respuesta por token en entornos agentivos donde el TPS es el verdadero diferencial competitivo.

Fuente de la imagen: Taalas
HC1: 6 nm, 815 mm² y límites de escalabilidad
Desde el punto de vista técnico, el HC1 se fabrica en el nodo de 6 nm de TSMC y alcanza hasta 815 mm², un tamaño comparable a aceleradores de gama alta del sector. El chip integra un modelo de 8.000 millones de parámetros, lo que explica sus cifras de rendimiento en ese rango específico.
El reto aparece al escalar. Los modelos frontera actuales superan el billón de parámetros, lo que obligaría a rediseñar el silicio para cada salto de escala. La propia Taalas plantea un enfoque por clúster y asegura haber alcanzado 12.000 TPS por usuario en una configuración de 30 chips con DeepSeek R1.
Análisis: velocidad extrema, pero hardware rígido
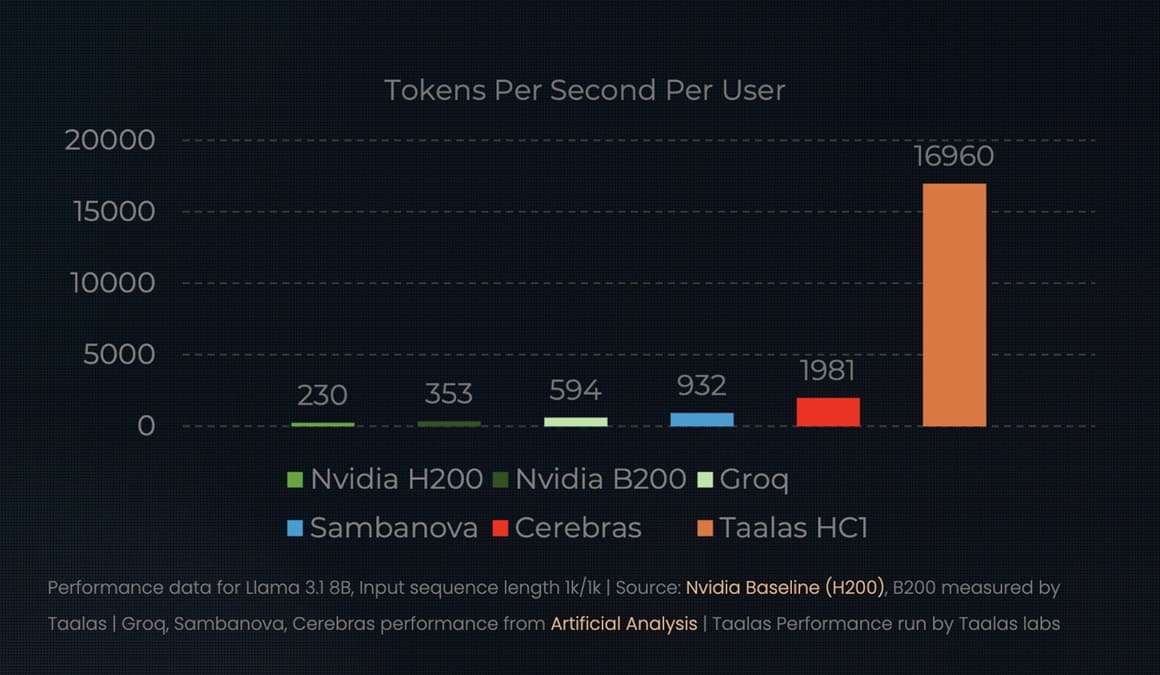
Fuente de la imagen: Taalas
La gran ventaja del enfoque es evidente: latencia reducida, alto TPS y costes controlados al eliminar complejidad externa. Sin embargo, el modelo “hardwired” implica que el hardware queda atado a un LLM concreto, sin posibilidad de modificar pesos o adaptar arquitecturas sin rediseño físico.
Desde una perspectiva estratégica, Taalas no compite frontalmente con fabricantes de silicio de GPU generalista, sino que propone una capa especializada para despliegues concretos. Si el mercado prioriza rendimiento por token y eficiencia energética sobre flexibilidad, este tipo de ASIC podría ganar tracción. En caso contrario, la rigidez del enfoque podría limitar su adopción masiva.
En definitiva, Taalas plantea una alternativa radical al modelo dominante: menos versatilidad, pero potencialmente más velocidad y menor coste por inferencia.
Vía: Wccftech










