Skymizer ha presentado la nueva HTX301, una tarjeta aceleradora PCIe orientada a inferencia de IA en local que promete ejecutar modelos de hasta 700B parámetros sin depender de grandes clusters de GPU. La compañía taiwanesa plantea esta solución para empresas que necesitan latencia determinista, soberanía de datos y costes de infraestructura más controlados.
La propuesta llama la atención porque trabaja con un consumo anunciado de solo 240W, una cifra muy inferior a la de varios aceleradores PCIe de gama alta actuales. Sobre el papel, HTX301 busca llevar grandes modelos de lenguaje a servidores locales, reduciendo dependencia del cloud y de instalaciones masivas con múltiples GPU.
Una tarjeta PCIe pensada para inferencia local
La Skymizer HTX301 adopta un formato de tarjeta PCIe convencional, pero su diseño está centrado específicamente en inferencia de grandes modelos de lenguaje. La compañía la sitúa dentro de su plataforma HyperThought, basada en una nueva generación de LPU IP orientada a mejorar eficiencia, compresión y rendimiento por vatio.
Según Skymizer, cada placa integra seis chips HTX301, pese a estar fabricados bajo un proceso de 28 nm. El dato resulta llamativo porque la compañía no apuesta por un nodo puntero, sino por una arquitectura especializada capaz de compensar limitaciones de fabricación mediante memoria, compresión y eficiencia dedicada.
Este enfoque la aleja de los aceleradores generalistas pensados para cubrir entrenamiento, inferencia y cargas mixtas. La HTX301 parece más orientada a un escenario concreto: ejecutar modelos grandes en instalaciones locales, con un consumo relativamente contenido y una arquitectura optimizada para decodificación y orquestación de inferencia.

Hasta 384 GB de memoria sin recurrir a HBM
Uno de los apartados más importantes está en la capacidad de memoria. La tarjeta puede integrar hasta 384 GB de memoria, utilizando DRAM estándar LPDDR4 y LPDDR5 en lugar de soluciones más caras como HBM, GDDR6 o GDDR7. Esta elección apunta a reducir costes y simplificar el diseño.
La estrategia tiene sentido si el objetivo principal es inferencia local con modelos grandes, donde la capacidad puede pesar más que el ancho de banda extremo. Skymizer afirma que el diseño está optimizado para menores requisitos de ancho de banda DRAM y cargas con alto volumen de parámetros, algo clave en despliegues empresariales.
Rendimiento centrado en LLMs de gran tamaño
La compañía asegura que el chip puede alcanzar 30 tokens por segundo con 0,5 TOPS y 100 GB/s de ancho de banda, una cifra con la que busca destacar su eficiencia frente a soluciones más generalistas. Además, el diseño Octa-Core LPU llegaría a 240 tokens por segundo en Llama2 7B durante prefill.
Skymizer también afirma que varios chips pueden conectarse entre sí para alcanzar hasta 1.200 tokens por segundo en el mismo LLM, manteniendo compatibilidad con modelos de hasta 700B parámetros. Aun así, estas cifras deberán comprobarse en pruebas reales, especialmente con modelos actuales y cargas empresariales sostenidas.
La compresión será una pieza clave
La arquitectura HTX301 también se apoya en técnicas de compresión para reducir requisitos de memoria y mejorar eficiencia. Skymizer habla de compresión de pesos para memoria a largo plazo, con una mejora frente a llama.cpp situada entre el 9% y el 17,8%, siempre según los datos facilitados por la compañía.
También se menciona compresión de caché KV para memoria a corto plazo, con una pérdida mínima de perplejidad situada entre el 0,06% y el 3,52%. Este apartado resulta especialmente importante porque la caché KV puede convertirse en un cuello de botella durante la inferencia con contextos largos y modelos muy grandes.
La lectura técnica es clara: Skymizer intenta reducir el coste de ejecutar LLMs grandes atacando dos frentes al mismo tiempo. Por un lado, aumenta la capacidad de memoria disponible; por otro, utiliza compresión de pesos y caché KV para rebajar presión sobre memoria, ancho de banda y consumo energético.
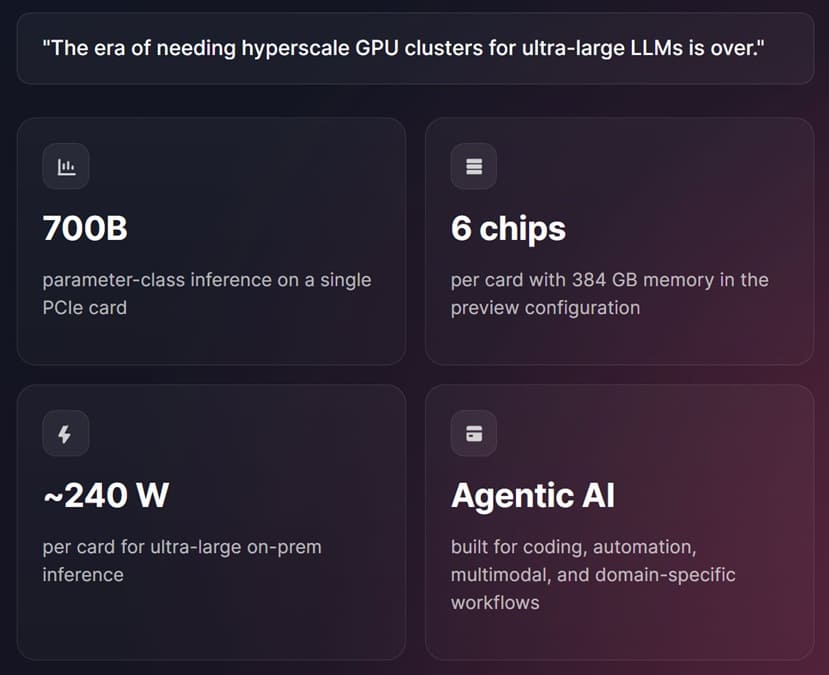
240W frente a aceleradores PCIe de 600W
El consumo es uno de los puntos más agresivos de la propuesta. Skymizer sitúa la HTX301 en solo 240W, menos de la mitad que aceleradores PCIe de referencia como la NVIDIA RTX PRO 6000 Blackwell o la AMD Instinct MI350P, ambas con consumos cercanos a los 600W.
Si estas cifras se confirman, la tarjeta podría resultar atractiva para empresas que buscan inferir modelos grandes en servidores locales sin rediseñar por completo energía, refrigeración o infraestructura. El enfoque no parece competir contra clústeres de entrenamiento, sino contra despliegues de inferencia donde el coste operativo pesa mucho.
Una propuesta prometedora, pero todavía por validar
Skymizer mostrará la HTX301 durante Computex, donde será importante comprobar si las cifras anunciadas se mantienen en demostraciones reales. La idea de ejecutar modelos de 700B parámetros en una sola tarjeta PCIe resulta muy ambiciosa, especialmente con memoria LPDDR estándar, nodo de 28 nm y consumo de 240W.
Sobre el papel, la propuesta puede abrir una vía interesante para empresas pequeñas y medianas que quieren mantener IA en local. Aun así, el verdadero valor dependerá de rendimiento sostenido, compatibilidad con frameworks, calidad de compresión y facilidad de integración dentro de servidores ya existentes.
La clave estará en separar promesa técnica y rendimiento real. Si Skymizer consigue demostrar que la HTX301 mantiene latencia estable, buen throughput y compatibilidad práctica con LLMs actuales, podría convertirse en una alternativa muy interesante para inferencia local sin la complejidad de un clúster GPU tradicional.
Vía: Wccftech