El sector de IA está entrando en una fase donde la inferencia deja de ser secundaria para convertirse en el eje del rendimiento real en producción. Tras el giro de NVIDIA hacia modelos de inferencia desagregada, la alianza entre Intel y SambaNova introduce una arquitectura heterogénea, donde cada bloque de hardware se especializa en una tarea concreta. Este enfoque permite una asignación eficiente de recursos, optimizando el comportamiento en IA agentica y cargas generativas complejas.
Este cambio no es incremental, es un cambio estructural en el diseño de infraestructuras de IA. El modelo “GPU para todo” empieza a mostrar límites claros en latencia, consumo energético y eficiencia sostenida, especialmente en inferencia continua. Aquí es donde esta propuesta cobra sentido, al aplicar una distribución optimizada entre prefill, decode y orquestación, lo que permite reducir cuellos de botella, estabilizar el rendimiento y mejorar la eficiencia en producción real.
Inferencia desagregada: dividir el pipeline para escalar mejor

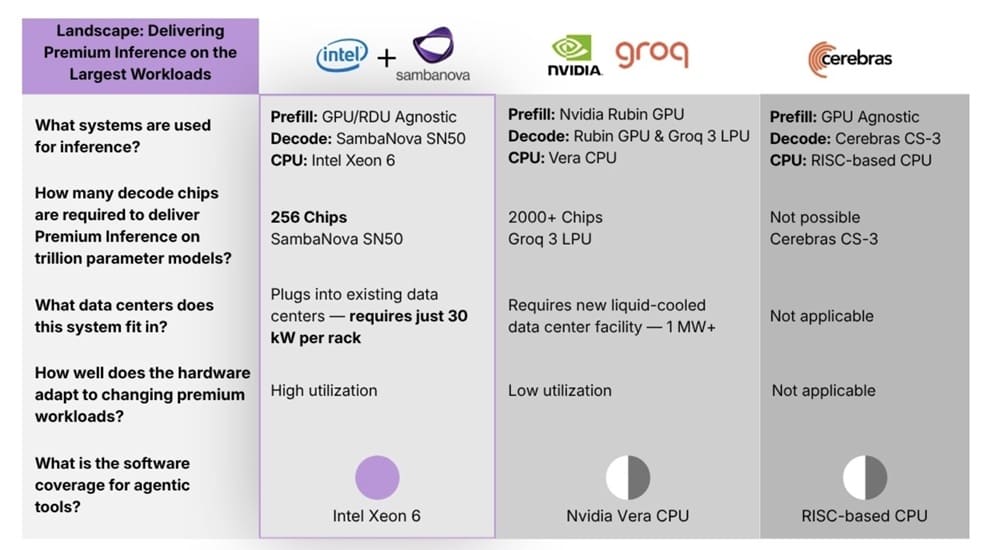
La arquitectura propuesta divide el pipeline de inferencia en fases claramente diferenciadas, donde las GPU se encargan del prefill inicial, preparando los datos y el contexto del modelo, mientras que las RDUs asumen el decode en modelos generativos, una de las fases más críticas por su impacto en la latencia. Este reparto permite una optimización específica por tipo de carga, evitando que un único tipo de hardware se convierta en cuello de botella.
Por su parte, los Intel Xeon 6 actúan como CPU host y núcleo de orquestación, gestionando el flujo de datos, coordinando tareas y ejecutando operaciones generales del sistema. Este diseño permite una mejor utilización del hardware disponible, reduce redundancias en la ejecución y mejora la eficiencia global del sistema frente a arquitecturas monolíticas basadas exclusivamente en GPU, especialmente en entornos de inferencia sostenida.
Xeon 6 vuelve a tener un papel central en la IA
En esta arquitectura, los Xeon 6 no son un componente auxiliar, sino una pieza clave dentro del sistema. Intel los posiciona como fundamentales para la gestión de agentes, ejecución general y control del pipeline, donde la flexibilidad de la CPU sigue siendo determinante frente a aceleradores especializados. Esto es especialmente relevante en entornos donde la lógica y la coordinación pesan tanto como el cálculo bruto.
SambaNova destaca incluso ventajas frente a ARM en escenarios de “flujos de trabajo completos para agentes de código”, lo que refuerza su papel en cargas complejas. Este detalle indica que la CPU recupera protagonismo en un ecosistema dominado por GPU, especialmente en tareas de coordinación, control y ejecución de lógica dentro de sistemas de IA avanzados.
SN50: una arquitectura de memoria pensada para inferencia

El SN50 es el componente más diferencial de esta propuesta, basado en RDUs de quinta generación optimizadas para inferencia, y con un diseño claramente centrado en memoria. Integra 2 TB de DDR5, 64 GB de HBM3 y 520 MB de SRAM, una combinación diseñada para reducir latencia, maximizar throughput y minimizar accesos a memoria externa, algo clave en modelos de gran tamaño.
Este enfoque permite mantener los datos más cerca del procesamiento, reduciendo tiempos de acceso y mejorando la eficiencia global. Según SambaNova, esta arquitectura habilita el concepto de “agentic caching optimizado para IA”, lo que mejora el rendimiento en modelos complejos donde la memoria se convierte en el principal cuello de botella del sistema.
Frente a NVIDIA: modularidad frente a integración total
La diferencia frente a NVIDIA no es solo técnica, sino también estratégica. Mientras NVIDIA apuesta por un ecosistema cerrado, altamente integrado y dependiente de su stack, Intel y SambaNova proponen un modelo basado en modularidad y flexibilidad de integración, permitiendo adaptar la infraestructura según necesidades concretas.
Este enfoque permite combinar GPU, ASICs y RDUs dentro de un mismo sistema, sin depender de un único proveedor. Para hyperscalers, esto supone una ventaja clara, ya que pueden diseñar infraestructuras optimizadas en torno al esquema prefill + decode, ajustando costes, rendimiento y consumo energético de forma mucho más precisa.
Estrategia pragmática centrada en adopción real
Intel no está intentando redefinir el mercado de forma agresiva, sino posicionarse con una solución viable y escalable en entornos reales. En lugar de construir un ecosistema cerrado desde cero, se apoya en su fortaleza en CPU y colabora con SambaNova para cubrir el resto del stack de inferencia.
Este enfoque permite una integración más sencilla en infraestructuras existentes, reduciendo barreras técnicas y facilitando una transición progresiva hacia modelos de inferencia más eficientes, algo especialmente relevante en despliegues empresariales donde el coste de migración es un factor crítico.
Relación estratégica con implicaciones a largo plazo
La colaboración entre ambas compañías no se limita al plano técnico, sino que también tiene un componente estratégico relevante. El CEO de Intel, Lip-Bu Tan, ha participado en la financiación de SambaNova, reforzando una relación con implicaciones a largo plazo en el sector de IA.
Aunque en su momento se planteó una posible adquisición, esta no llegó a materializarse. Intel ha optado por una estrategia de inversión y colaboración, alineando intereses sin integración total, lo que encaja con su posicionamiento actual dentro del sector de IA e infraestructuras de inferencia avanzadas.
Vía: Wccftech