El sector de infraestructuras para inteligencia artificial continúa avanzando hacia arquitecturas optimizadas para cargas complejas, y nuevas pruebas realizadas sobre los sistemas NVIDIA GB300 NVL72 muestran mejoras claras frente a la generación GB200 NVL72. Evaluaciones llevadas a cabo por el equipo LMSYS utilizando modelos abiertos de DeepSeek revelan avances relevantes en inferencia de contexto largo, un escenario cada vez más habitual en aplicaciones modernas de IA agentic.
La arquitectura Blackwell Ultra busca mejorar el equilibrio entre rendimiento, latencia y eficiencia energética, factores que se han convertido en prioritarios a medida que los modelos aumentan su tamaño y el volumen de datos procesados crece de forma exponencial.
Blackwell Ultra prioriza el rendimiento en inferencia de contexto largo
Con la plataforma GB300, NVIDIA centra su estrategia en optimizar el procesamiento de contextos extensos, donde la carga de trabajo se desplaza hacia la memoria de GPU y la gestión eficiente de tokens. Según datos técnicos previos, la nueva arquitectura alcanza hasta 50× más rendimiento por megavatio frente a la generación Hopper, gracias a un diseño conjunto de hardware y software orientado específicamente a IA.
Las pruebas del grupo Large Model Systems Organization (LMSYS) analizaron escenarios reales de inferencia prolongada, evaluando el comportamiento del sistema bajo condiciones propias de centros de datos dedicados a inteligencia artificial avanzada.
Este enfoque refleja un cambio dentro del sector, donde el rendimiento ya no depende únicamente de la potencia bruta, sino de la eficiencia global del sistema completo.
Desagregación Prefill-Decode para evitar cuellos de botella
Para gestionar grandes volúmenes de contexto, el equipo LMSYS implementó la técnica desagregación Prefill-Decode, un método que divide el procesamiento entre distintos nodos de hardware para reducir bloqueos durante la ejecución.
La fase prefill, encargada del procesamiento inicial del prompt, y la fase decode, responsable de la generación de tokens, se ejecutan de forma distribuida, permitiendo mejorar la escalabilidad del sistema y aumentar el rendimiento sostenido en inferencia masiva.
Además, se aplicaron optimizaciones como el fragmentado dinámico del contexto y una gestión avanzada de la memoria KV, elementos fundamentales para mantener coherencia y velocidad cuando se trabajan modelos de gran tamaño.
El análisis se centró en métricas clave como rendimiento por GPU, capacidad operativa y latencia, actualmente consideradas los indicadores más relevantes en infraestructuras de IA generativa.
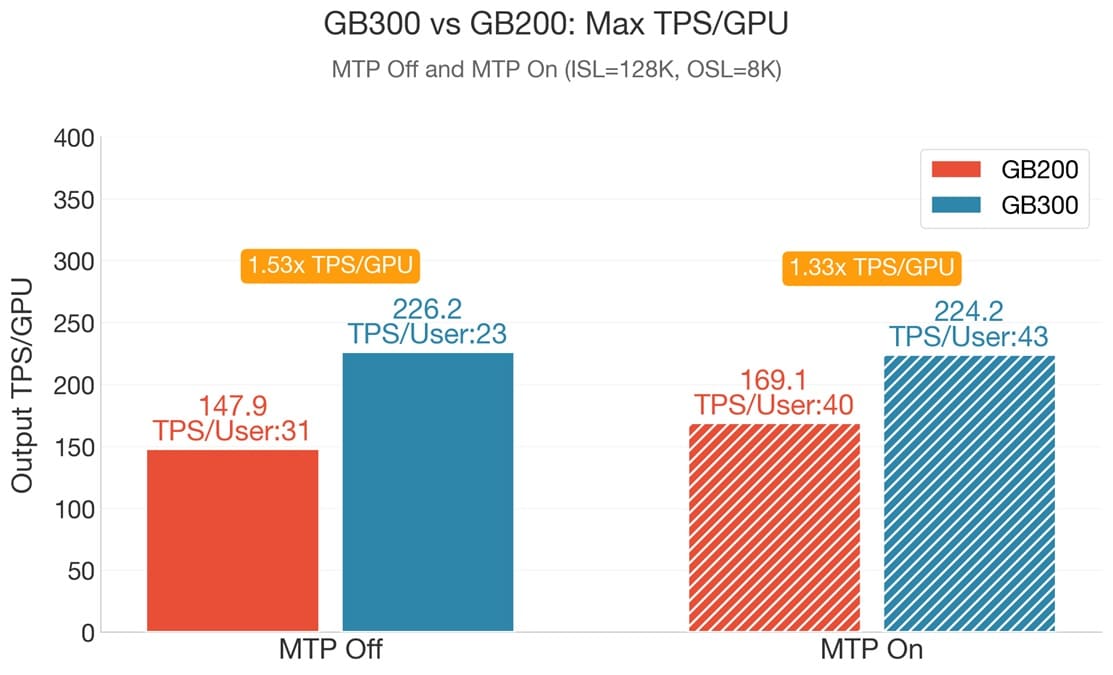
Fuente de la imagen: LMSYS
Resultados: mejoras claras frente a GB200 NVL72
Las comparativas directas entre ambas generaciones muestran avances consistentes en múltiples métricas críticas:
- 1,53× más rendimiento máximo: 226,2 tokens por segundo por GPU
- 1,87× mayor velocidad por usuario mediante predicción múltiple de tokens
- 1,58× mejora en latencia en escenarios sensibles al tiempo de respuesta
Según LMSYS, el sistema GB300 NVL72 mantiene una ventaja media de entre 1,4× y 1,5× frente al modelo anterior, especialmente en cargas donde la latencia resulta determinante para la interacción en tiempo real.
Estas mejoras consolidan a Blackwell Ultra como una arquitectura diseñada específicamente para las nuevas generaciones de aplicaciones basadas en agentes de IA.
Latencia, costes y adopción en centros de datos
Aunque los resultados muestran ventajas claras en rendimiento, todavía no existen cifras públicas completas sobre el coste total de propiedad (TCO), un factor clave dado que los sistemas GB300 incrementan los costes de despliegue respecto a generaciones previas.
La estrategia de NVIDIA parece orientarse a resolver limitaciones estructurales del sector, priorizando mejoras en latencia, eficiencia energética y escalabilidad antes que incrementos puramente teóricos de potencia.
Precisamente por estas características, los sistemas GB300 NVL72 comienzan a atraer el interés de grandes operadores de centros de datos y proveedores de nube especializada, donde las cargas agentic requieren respuestas rápidas y consistentes bajo grandes volúmenes de inferencia.
El avance confirma que la competición actual en inteligencia artificial ya no gira únicamente en torno al tamaño del modelo, sino a la eficiencia integral del sistema capaz de ejecutarlo.
Vía: Wccftech