AMD ha presentado la nueva versión ROCm 7.0, un salto importante dentro de su ecosistema de software para computación acelerada por GPU. La actualización se centra en optimizar el entrenamiento de grandes modelos de lenguaje (LLM) a través de los frameworks JAX y PyTorch, alcanzando una eficiencia de escalado superior en configuraciones tanto de nodo único como multinodo.
La compañía destaca que el entorno de entrenamiento v25.9 Docker ofrece una escalabilidad excepcional, permitiendo a los investigadores ampliar el tamaño y la complejidad de los modelos más allá de los límites habituales en hardware comercial.
Primus unifica la formación LLM en AMD Instinct
El pilar de esta versión es Primus, un framework de entrenamiento unificado y flexible para LLM, ahora integrado en los contenedores PyTorch v25.9. Este entorno simplifica el desarrollo modular sobre GPU AMD Instinct, incorporando compatibilidad con los backends TorchTitan y Megatron-LM.
Además, Primus-Turbo, una librería enfocada en acelerar modelos Transformer, mejora el rendimiento de entrenamiento sobre las AMD Instinct MI355X, reforzando su posición frente a alternativas como la NVIDIA B200.


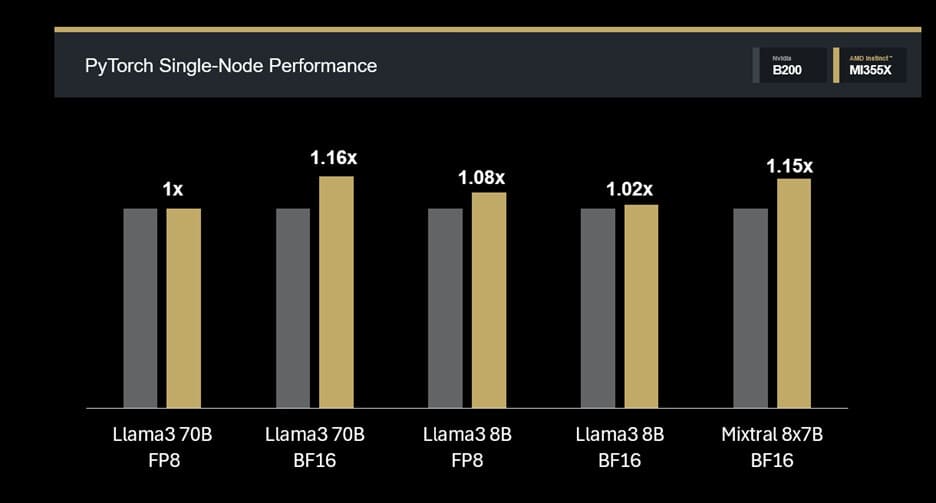
En pruebas internas, los resultados destacan:
- Llama3 70B FP8: rendimiento base (1,00×) en Primus-TorchTitan v25.9.
- Llama3 70B BF16: mejora del 16% (1,16×).
- Mixtral 8×7B FP16: aumento del 15% (1,15×).
Estos datos confirman la capacidad de la MI355X para manejar modelos densos y Mixture-of-Experts con un alto throughput de tokens incluso en nodo único.
JAX MaxText lleva el rendimiento a entornos científicos
JAX, conocido por su flexibilidad y enfoque funcional, recibe soporte optimizado mediante el nuevo Docker MaxText v25.9. Este paquete incluye JAX, XLA, librerías ROCm y utilidades MaxText preconfiguradas, facilitando el despliegue de entornos de entrenamiento listos para usar sobre hardware AMD.
En estas pruebas, las MI355X mostraron:
- Llama3.1 70B FP8: +11% frente a B200.
- Llama3.1 8B FP8: +7%.
- Mixtral 8×7B FP16: rendimiento equivalente (1,00×).
El resultado confirma que AMD Instinct MI355X mantiene mayor rendimiento en modelos densos y paridad en MoE, maximizando la escalabilidad de JAX en entornos científicos y de IA avanzada.


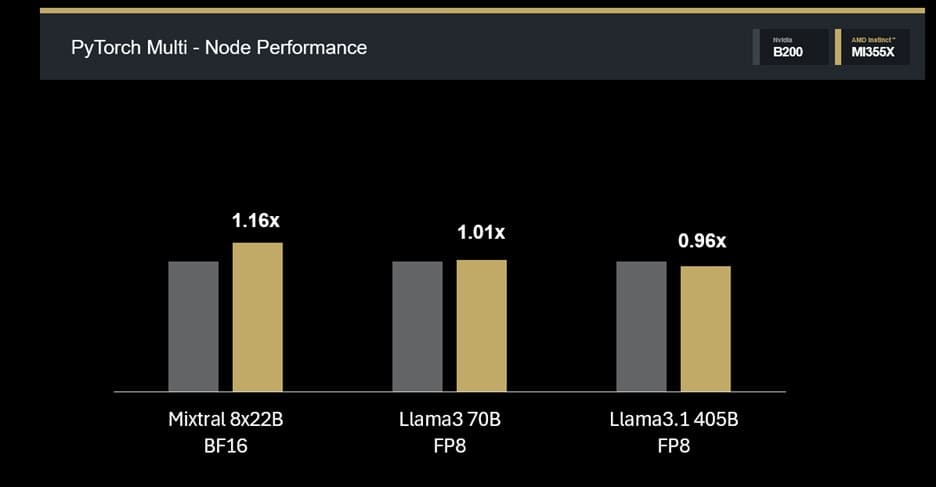
Escalado multinodo y eficiencia distribuida
En entornos distribuidos, MI355X conserva su eficiencia de forma notable:
- Mixtral 8×22B BF16: 1,14× de ventaja en 4 nodos.
- Llama3 70B FP8: paridad (1,01×).
- Llama3.1 405B FP8: rendimiento competitivo (0,96×) en 8 nodos.
Estos datos demuestran que las GPU MI355X no solo destacan en rendimiento por nodo, sino que también escalan eficazmente para entrenamiento LLM a gran escala, manteniendo una relación rendimiento-consumo muy competitiva frente a NVIDIA.
Una nueva referencia para el entrenamiento LLM
Con ROCm 7.0 y las GPU Instinct MI355X, AMD consolida un ecosistema completo que combina software optimizado, escalabilidad multinodo y mayor eficiencia en transformers.
El lanzamiento de Primus y MaxText permite a los desarrolladores entrenar modelos de próxima generación sin ajustes complejos, reforzando la estrategia de AMD en el sector de IA de alta computación.
Como afirma la compañía, “ROCm 7.0 establece una base sólida para ampliar los límites del entrenamiento LLM a escala mundial”.
Vía: TechPowerUp