NVIDIA ha anunciado CUDA 13.1, una versión histórica de su plataforma de computación paralela que introduce CUDA Tile, un nuevo modelo de programación basado en bloques o tiles. Se trata del mayor avance en CUDA desde su creación en 2006, al permitir escribir algoritmos de alto nivel que abstraen los detalles del hardware especializado, como los tensor cores o los Tensor Memory Accelerators (TMA).
Este enfoque eleva la programación paralela a una capa más abstracta y eficiente, facilitando el desarrollo de código que podrá ejecutarse con compatibilidad nativa en generaciones futuras de GPU sin modificaciones profundas.
Una nueva forma de programar la GPU
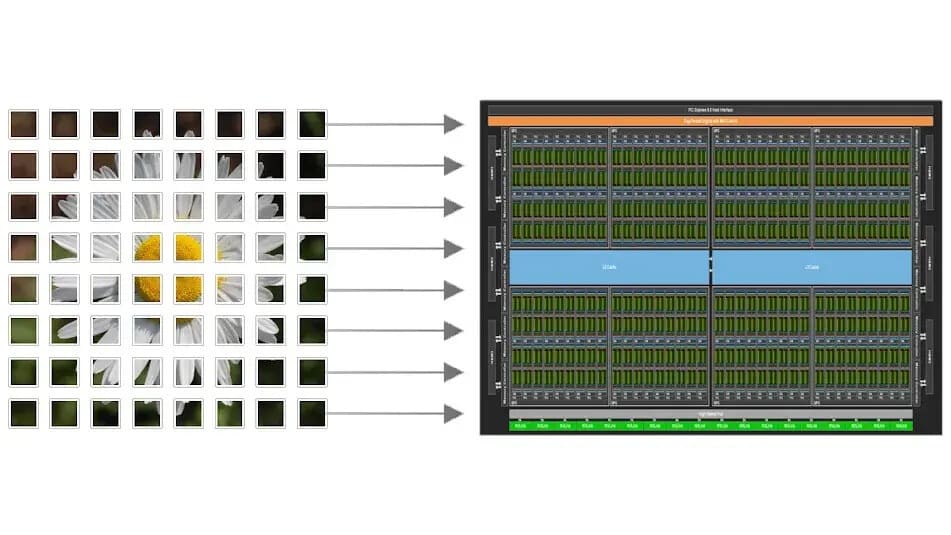
Hasta ahora, CUDA se basaba en el modelo SIMT (Single-Instruction, Multiple-Thread), que otorga control granular sobre cada hilo de ejecución, pero requiere un gran esfuerzo de optimización. CUDA Tile cambia este paradigma: los desarrolladores definen bloques de datos (tiles) y operaciones sobre ellos, mientras que el compilador y el runtime se encargan de mapear esas operaciones al hardware subyacente.
El resultado es un modelo más próximo a lenguajes como Python, donde librerías como NumPy permiten operar con matrices de forma sencilla y eficiente sin preocuparse por los detalles internos.
CUDA Tile IR: el núcleo del nuevo ecosistema
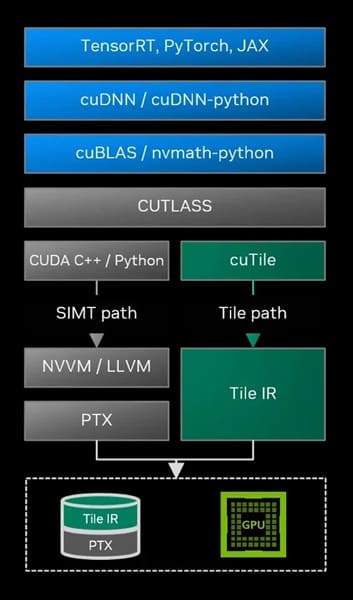
La base técnica de esta evolución es CUDA Tile IR (Intermediate Representation), una capa intermedia que introduce un conjunto de instrucciones virtuales para la programación basada en bloques. Esta capa permite que el código se ejecute de forma óptima y portable a lo largo de distintas arquitecturas de GPU.
Así como PTX garantizó portabilidad en los programas SIMT, Tile IR amplía el ecosistema CUDA hacia un modelo híbrido que coexiste con el enfoque tradicional. Los desarrolladores podrán seguir escribiendo kernels clásicos cuando necesiten un control detallado, o bien usar tile kernels para explotar al máximo los tensor cores.

Del nivel bajo al alto: cuTile Python y nuevos DSL
La mayoría de los desarrolladores interactuarán con CUDA Tile mediante herramientas como cuTile Python, la implementación oficial de NVIDIA basada en Tile IR. Este entorno permitirá programar GPU usando Python, simplificando la creación de algoritmos paralelos para IA, entrenamiento de modelos o simulaciones científicas.
Para quienes desarrollen compiladores, librerías o lenguajes de dominio específico (DSLs), la documentación de Tile IR ya incluye las abstracciones, sintaxis y semántica necesarias para adaptar proyectos que actualmente se basan en PTX.
Un paso clave para el futuro de la IA
Con CUDA 13.1 y Tile IR, NVIDIA busca consolidar su liderazgo en el sector de la IA y el cómputo acelerado, facilitando herramientas más potentes, modulares y sostenibles. Este nuevo modelo promete acelerar el desarrollo de software científico y de aprendizaje automático, manteniendo la compatibilidad con las GPU actuales y las arquitecturas que vendrán.
En palabras de la propia compañía, “no es una elección entre SIMT o Tile, sino un paso hacia la coexistencia de ambos mundos para maximizar el rendimiento en cada escenario”.
Vía: TechPowerUp