La GPU H100 de NVIDIA está disponible desde hace poco para su uso a través de proveedores de servicios en la nube (CSP), y era solo cuestión de tiempo que alguien decidiera comparar su rendimiento con el de la GPU A100 de anterior generación.
Hoy, gracias a los benchmarks de MosaicML, una startup dirigida por el ex director general de Nervana y director general de Inteligencia Artificial (IA) en Intel, Naveen Rao, disponemos de una comparativa entre estas dos GPUs con una fascinante perspectiva sobre el factor coste.
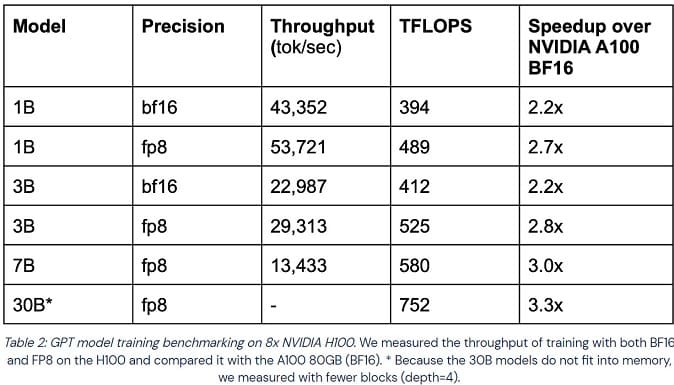
MosaicML ha tomado modelos Generative Pre-trained Transformer (GPT) de diversos tamaños y los ha entrenado utilizando formatos de precisión bfloat16 y FP8 Floating Point. Todo el entrenamiento se ha realizado en instancias de GPU en la nube CoreWeave.
En cuanto al rendimiento, la GPU NVIDIA H100 consiguió entre 2,2 y 3,3 veces más velocidad. Sin embargo, resulta interesante comparar el coste de ejecutar dichas GPUs en la nube. CoreWeave fija el precio de las GPUs H100 SXM en 4,76 dólares/hora/GPU, mientras que la A100 80 GB SXM obtiene un precio de 2,21 dólares/hora/GPU.

Si bien el H100 es 2,2 veces más caro, el rendimiento lo compensa, lo que se traduce en menos tiempo para entrenar un modelo y un precio más asequible para el proceso de entrenamiento. Esto hace que la GPU H100 resulte más atractiva para los investigadores y las empresas que desean entrenar grandes modelos lingüísticos (LLM) y hace que la elección de la nueva GPU sea más viable, a pesar de su mayor coste.
En este mismo post podéis ver tablas comparativas entre dos GPUs en cuanto a tiempo de entrenamiento, aceleración y coste del entrenamiento.
Vía: TechPowerUp