
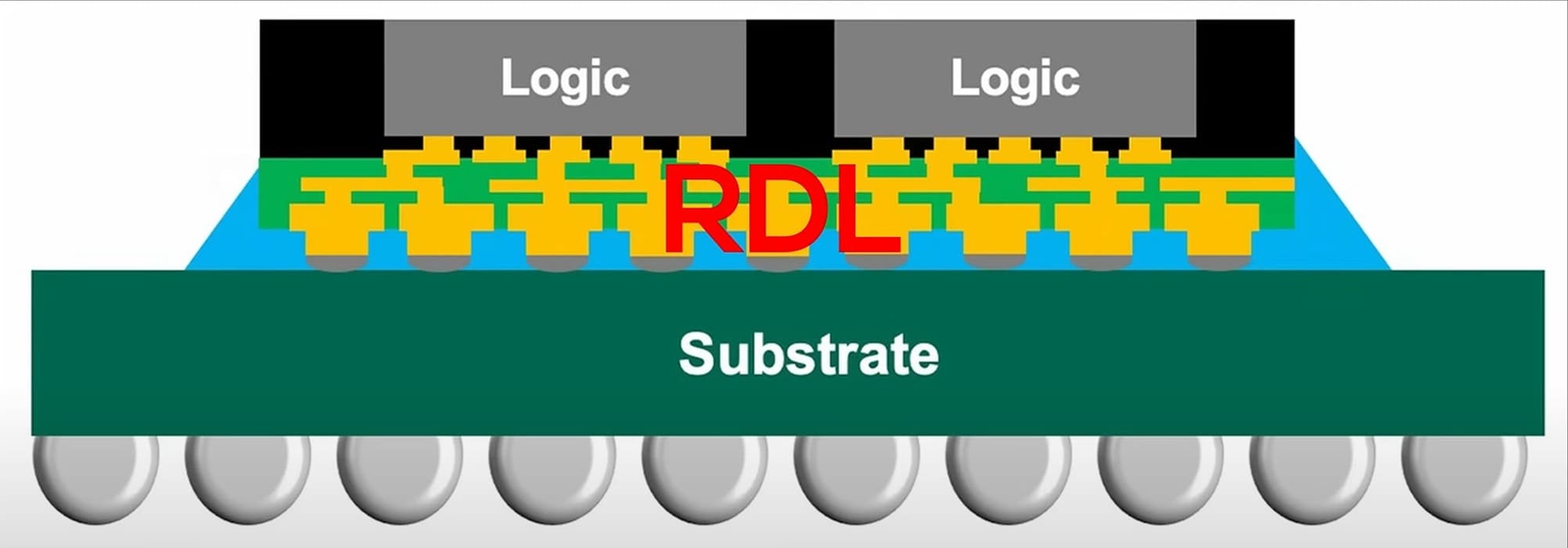
Según el canal High Yield, AMD estaría virando de enlaces die-to-die SERDES a un esquema paralelo tipo sea-of-wires en Strix Halo, enrutado mediante fan-out y RDL. Las fotos de muestras muestran un campo rectangular de pads donde cabría esperar el fan-out y la ausencia del gran bloque SERDES que solía ubicarse en los bordes de los CCD. El patrón, sumado a elecciones de encapsulado compatibles con TSMC InFO-oS, sugiere que AMD está probando trazas paralelas densas para que las lanes del fabric crucen el paquete sin canalizarse en unos pocos enlaces serie de muy alta velocidad.
De SERDES a “mar de cables” paralelos

Al serializar/deserializar en cada frontera de paquete se paga latencia por recuperación de reloj, ecualización y codificación/decodificación, además de consumo en las PHY. Con muchos hilos cortos en paralelo, se elimina trabajo PHY repetido y se reduce el round-trip delay, mientras que el ancho de banda bruto escala añadiendo más pistas físicas.
Otro efecto colateral deseable es liberar área anteriormente ocupada por grandes bloques SERDES, permitiendo acercar CCDs, controladores de memoria e IPs de aceleración y bajando el coste de comunicación interna.

Retos de señal, térmica y fabricación
Empaquetar cientos o miles de trazas paralelas bajo el die impone desafíos:
- Integridad de señal (skew, crosstalk, pérdidas en RDL).
- Gestión térmica y apilado de capas RDL.
- Enrutado complejo y rendimiento manufacturable (yield).
Superarlos exige co-diseño estrecho entre equipos de diseño de chip y paquete, y RDL multicapa bien modelado. En paralelo, habrá que afinar terminaciones, timing y calibración para mantener márgenes sin recurrir a bloques analógicos costosos.
Implicaciones para Zen 6 y el IMC
Si AMD resuelve estos compromisos y lleva el enfoque a Zen 6, podrían verse mejoras reales por vatio y en latencia para cargas de CPU:
- IMC más rápido por la menor latencia hacia el die de I/O.
- Fabric con más ancho de banda agregado sin subir tanto la frecuencia.
- Menor jitter y colas de cola en tráfico mixto CPU-GPU-NPU dentro del paquete.
A más largo plazo, un sea-of-wires denso facilita chiplets heterogéneos (CPU, GPU, NPU, HBM/LPDDR estacado) en topologías menos constreñidas por los “cuellos de botella” SERDES, y se alinea con tendencias de CPO y memorias anchas dentro del propio módulo.
Estado actual
Por ahora son indicios en Strix Halo: un padfield rectangular, la ausencia del macro SERDES típico y pistas de InFO-oS. Aun así, el cambio encaja con la presión de latencia/energía que imponen AI/HPC y el auge de APUs grandes con fabrics internos cada vez más anchos.
Vía: TechPowerUp










