AMD ha publicado un nuevo trabajo de investigación en el que explora una evolución directa de su tecnología 3D V-Cache: el apilado vertical de caché L2, no solo de L3, en futuros chips. El estudio, titulado Balanced Latency Stacked Cache y registrado bajo la patente US20260003794A1, describe un enfoque que promete igualar o incluso mejorar la latencia de las cachés L2 tradicionales, al tiempo que reduce el consumo energético.
La propuesta parte de una premisa clara: el apilado en 3D no tiene por qué penalizar el acceso a niveles de caché sensibles a la latencia, como la L2, algo que históricamente ha limitado este tipo de diseños a niveles más grandes como la L3.
De la 3D V-Cache L3 a una posible L2 apilada

Hasta la fecha, AMD ha utilizado 3D V-Cache exclusivamente para añadir caché L3 adicional, tanto en procesadores Ryzen X3D de consumo como en soluciones profesionales de la familia EPYC. En la primera generación, la caché se apilaba sobre el chiplet de cómputo, mientras que en la segunda pasó a situarse debajo, mejorando la gestión térmica.
El nuevo planteamiento va un paso más allá: apilar también la caché L2, un nivel crítico por su cercanía a los núcleos y su impacto directo en el rendimiento por ciclo. Según el documento, AMD considera viable este enfoque siempre que se controle cuidadosamente la latencia.
Arquitectura propuesta: latencia equilibrada en vertical
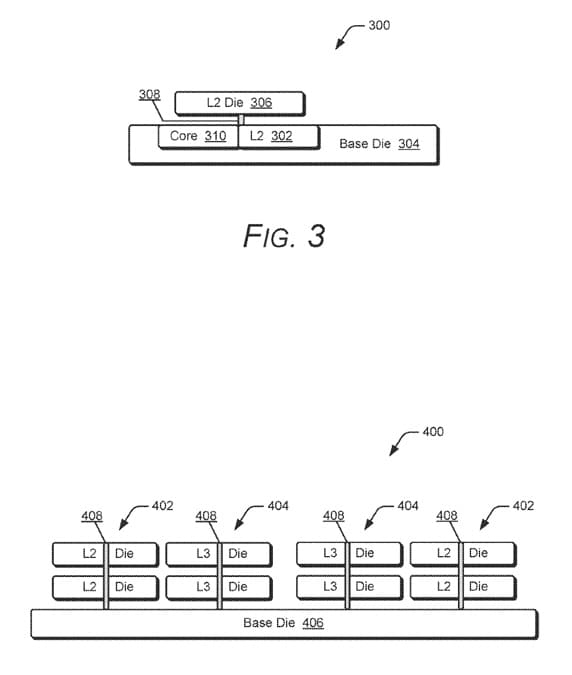
El diseño descrito utiliza un dado base conectado a un dado de cómputo y a uno o varios dados de caché, con la posibilidad de seguir apilando capas adicionales. En el ejemplo ilustrativo, AMD describe un módulo de caché L2 de 2 MB, dividido en cuatro regiones de 512 KB, gestionadas por un bloque específico llamado Cache Control Circuitry (CCC).
La interconexión entre capas se realiza mediante vías de silicio verticales, situadas en el centro del sistema de caché apilado. Este detalle es clave, ya que permite latencias simétricas entre las distintas mitades de la caché, evitando recorridos largos de señal que penalizan a los diseños planos.
Menor latencia que una L2 plana tradicional
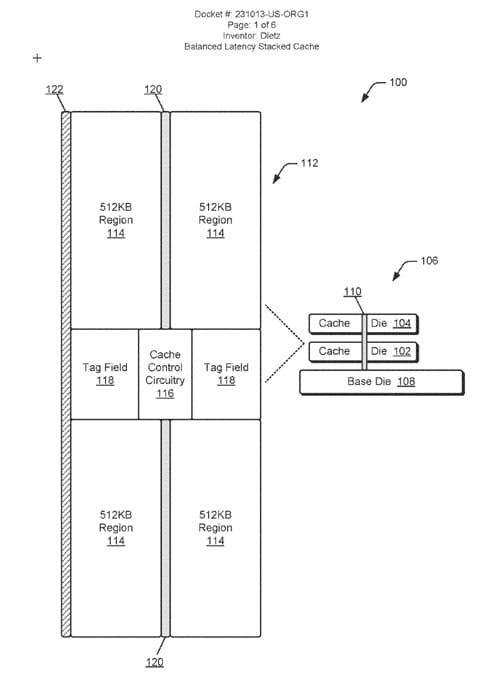
Uno de los datos más relevantes del estudio es la comparación directa de latencias. AMD señala que una caché L2 plana de 1 MB suele presentar una latencia de 14 ciclos, mientras que una L2 apilada de 1 MB basada en este diseño puede reducirla a 12 ciclos. Es decir, más capacidad sin penalización, e incluso con mejora frente al diseño convencional.
Este enfoque evita la necesidad de añadir etapas adicionales de cableado interno, reduciendo la longitud de las interconexiones y, con ello, la capacitancia, el consumo y la generación de calor.
Eficiencia energética como beneficio añadido
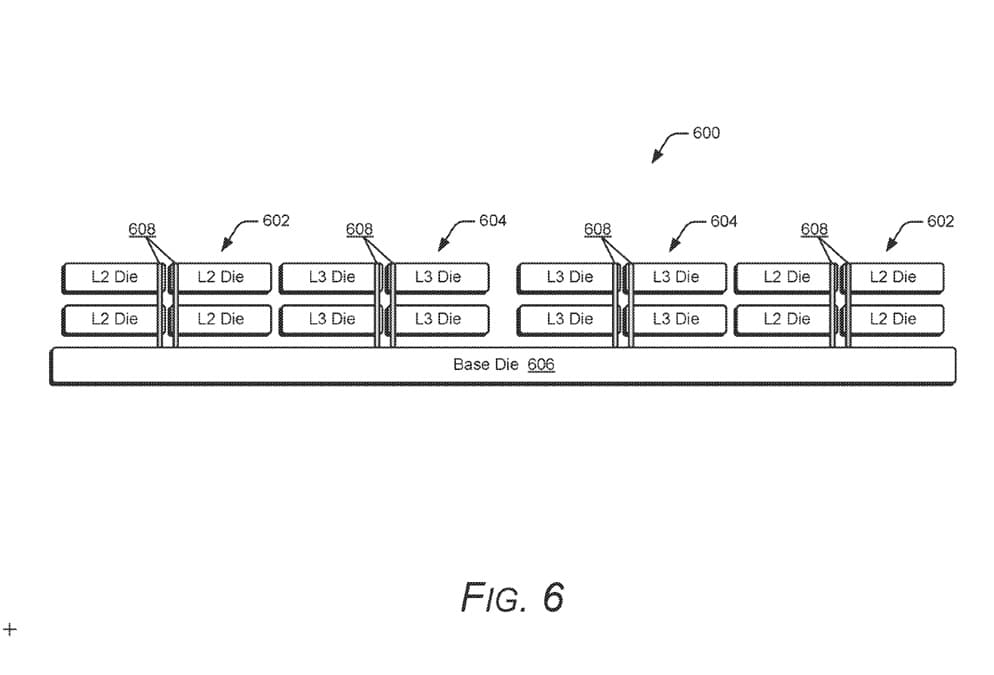
Además de la latencia, AMD destaca ahorros energéticos significativos. Al completarse los accesos en menos ciclos, la caché permanece activa durante menos tiempo y puede volver antes a estados de bajo consumo. La reducción de longitud de los cables internos también disminuye la carga de señal, contribuyendo a una mejor eficiencia energética global.
Estos factores hacen que la caché L2 apilada no solo sea atractiva desde el punto de vista del rendimiento, sino también para chips con límites térmicos estrictos, como CPUs de alto rendimiento o incluso futuras GPUs.
Un vistazo al futuro del diseño de chips
Por ahora, esta tecnología se encuentra en fase de investigación y patente, y pasarán años antes de verla implementada en productos comerciales. Sin embargo, el precedente de 3D V-Cache sugiere que AMD no explora estas ideas de forma teórica sin una posible aplicación real.
Si llega a materializarse, el apilado de caché L2 podría marcar un nuevo paso en la evolución de los diseños basados en chiplets, ampliando el papel del empaquetado avanzado y del silicio apilado más allá de la L3. Una señal clara de que el futuro del rendimiento no solo depende del nodo, sino de cómo se organiza la jerarquía de memoria dentro del chip.
Vía: Wccftech