
Marvell ha aprovechado su Analyst Day 2025 para mostrar avances clave en su silicio personalizado, poniendo el foco en una SRAM IP de 2 nm que, según la compañía, supera de forma clara a las soluciones estándar del sector en consumo energético, densidad y rendimiento. Aunque esta IP de SRAM fue anunciada inicialmente en junio, ahora se han revelado datos técnicos concretos que permiten dimensionar mejor su impacto real en SoCs avanzados.
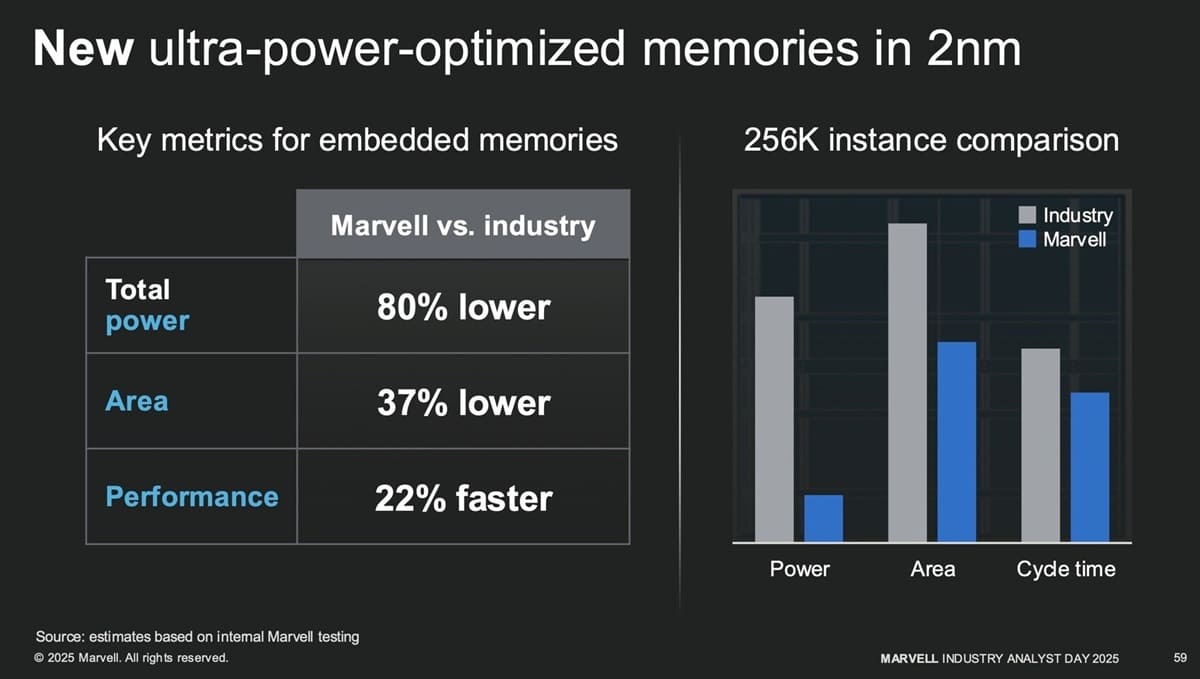
En una comparación directa con una instancia de 256 K, Marvell asegura que su diseño logra una reducción del 80% en el consumo total, ocupa un 37% menos de área y ofrece tiempos de ciclo un 22% más rápidos. Además, el layout más rectangular de la memoria facilita su integración en diseños de alta densidad, un factor cada vez más crítico en nodos punteros.
Menos área, menos consumo y mucho más ancho de banda
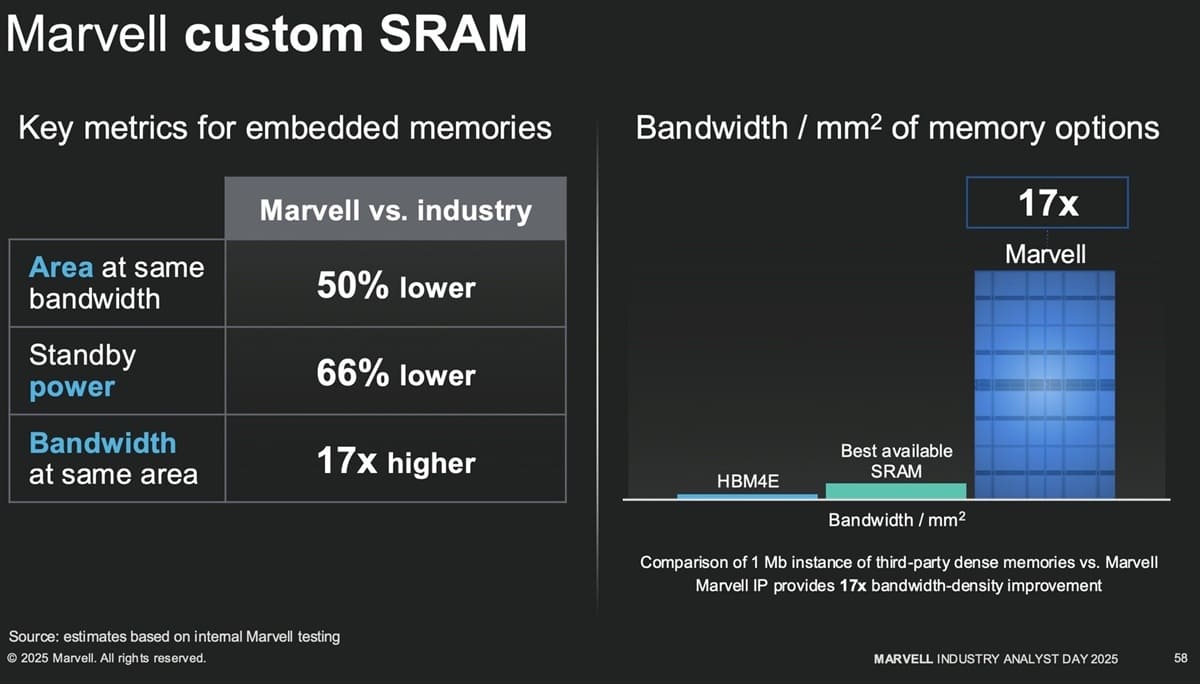
Frente a otras alternativas líderes del mercado, la SRAM personalizada de Marvell también destaca por utilizar un 50% menos de área a igual ancho de banda, reducir el consumo en reposo en un 66% y entregar hasta 17 veces más ancho de banda por mm² cuando se normaliza por superficie.
La compañía atribuye estos resultados a una reingeniería profunda de las estructuras de reloj y puertos, optimizadas para extraer más ancho de banda de la SRAM integrada en el silicio. Este enfoque arquitectónico permite alcanzar una densidad de ancho de banda muy superior, al tiempo que se contiene el consumo energético, uno de los grandes cuellos de botella en chips avanzados.
En un contexto donde la escalada de la lógica sigue avanzando más rápido que la de la memoria, disponer de IP personalizada de SRAM con estas características se convierte en una ventaja estratégica clave para diseños de alto rendimiento y eficiencia.
El problema histórico del escalado de la SRAM
Marvell ha contextualizado sus avances recordando una realidad conocida en la industria: el escalado de la SRAM no ha seguido el mismo ritmo que la lógica en los nodos más avanzados. Un ejemplo claro es TSMC N3, donde las celdas de SRAM son prácticamente idénticas a las de N5, con apenas un 5% de mejora real en densidad, mientras que la lógica sí logra un escalado de transistores de 1,56x de N5 a N3.
Dado que la SRAM ocupa una parte muy significativa del área total y del presupuesto de transistores de un procesador moderno, esta falta de escalado convierte el uso de nodos como N3B en una decisión difícil de justificar desde el punto de vista del coste, especialmente cuando el ahorro de área es mínimo.
Durante años, la memoria y la lógica avanzaron de forma desigual, pero en los nodos más recientes la divergencia es ya total. De cara a N2 y nodos aún más pequeños, el sector asume que esta situación se mantendrá, incrementando la presión sobre soluciones alternativas.
SRAM personalizada como respuesta al coste de los nodos avanzados
En este escenario, la propuesta de Marvell apunta directamente al núcleo del problema: mejorar densidad y eficiencia sin depender del escalado físico del nodo. Al optimizar la arquitectura interna de la SRAM, la compañía consigue resultados prácticos que el proceso de fabricación por sí solo ya no puede ofrecer.
Para SoCs complejos, aceleradores de IA, chips de red y procesadores de alto rendimiento, donde la SRAM on-die es crítica para latencias y ancho de banda, este tipo de IP personalizada puede marcar la diferencia entre un diseño viable y uno penalizado por coste, consumo o superficie.
En conjunto, los datos presentados por Marvell refuerzan una tendencia clara en el sector de semiconductores: el futuro del rendimiento ya no depende solo del nodo, sino de arquitecturas de memoria cada vez más agresivas, capaces de compensar las limitaciones físicas y económicas del escalado tradicional.
Vía: TechPowerUp










