
Durante el AI Infra Summit, NVIDIA presentó oficialmente el Rubin CPX, un nuevo acelerador gráfico derivado de la próxima familia Rubin. Este chip está diseñado específicamente para modelos de IA de gran contexto, capaces de procesar millones de tokens de manera simultánea, una capacidad clave para aplicaciones que van desde el análisis de código de software a gran escala hasta el procesamiento de vídeos de varias horas.
30 PetaFLOPS y 128 GB GDDR7 en un único die
El Rubin CPX alcanza hasta 30 PetaFLOPS de rendimiento NVFP4 sobre un diseño monolítico, alejándose de los paquetes de doble GPU característicos de las arquitecturas Blackwell y Blackwell Ultra.
La GPU integra 128 GB de memoria GDDR7, lo que asegura un ancho de banda masivo para cargas de trabajo de IA. Aunque NVIDIA no ha confirmado la cifra exacta, se especula con un bus de 512 bits que, junto a chips de 30 Gbps, ofrecería un rendimiento de hasta 1,8 TB/s.


Triple velocidad frente a Blackwell Ultra
Según NVIDIA, el Rubin CPX logra un rendimiento 3 veces superior en operaciones de atención respecto a los actuales GB300 Blackwell Ultra, convirtiéndose en una referencia en entornos de inferencia de gran escala.
El chip también incluye cuatro codificadores NVENC y cuatro decodificadores NVDEC directamente en el die, optimizando los flujos de trabajo multimedia sin necesidad de procesadores externos.


Plataforma Vera Rubin NVL144 CPX
El Rubin CPX formará parte de la plataforma Vera Rubin NVL144 CPX, que combinará GPUs Rubin convencionales con estas variantes especializadas. En conjunto, un rack completo podrá entregar:
- 8 ExaFLOPS de potencia de cómputo agregada.
- 1,7 PB/s de ancho de banda de memoria.
- Interconexiones con ConnectX-9 a 1600G, switching con Spectrum-6 a 102,4T y ópticas co-integradas.
Este sistema, bautizado como Kyber rack, está previsto para su lanzamiento en finales de 2026, después del estreno de los Rubin estándar a comienzos del mismo año.
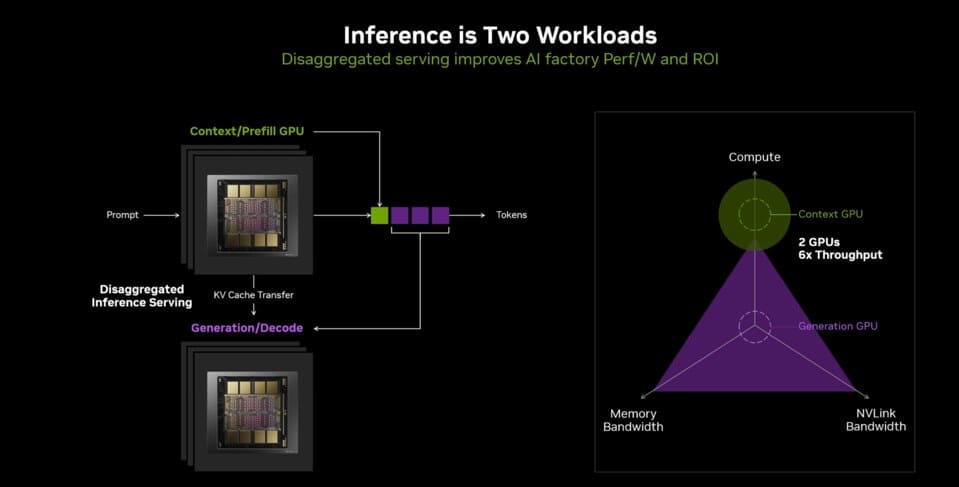
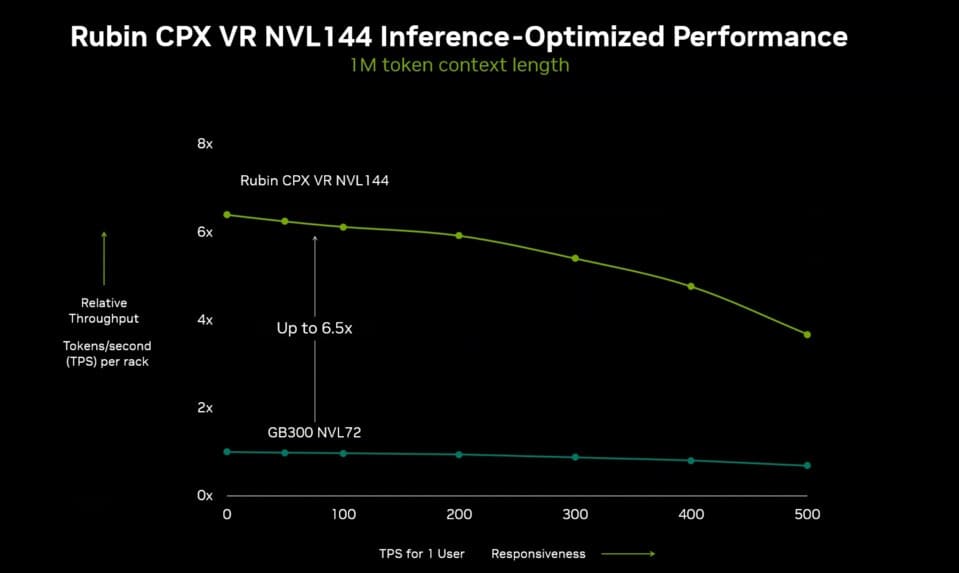
Optimización para IA de test-time scaling
El Rubin CPX es una solución singular dentro de la familia Rubin, concebida para responder a la creciente complejidad de la IA de razonamiento multietapa. Estos modelos ya no se limitan a la generación de texto, sino que requieren prefill de contexto con cientos de miles de tokens, junto a generación dependiente del ancho de banda de memoria.
El nuevo diseño busca precisamente optimizar estas dos fases críticas, permitiendo aplicaciones como chatbots empresariales con sesiones de 256.000 tokens o análisis de código de más de 100.000 líneas.
Vía: TechPowerUp










